
Индустрия искусственного интеллекта сместила фокус от обучения всё более крупных моделей к их масштабному развертыванию. К 2030 году рынок AI-инференса достигнет $254,98 млрд, при этом 70% спроса на центры обработки данных будет приходиться на приложения для AI-инференса. По мере перехода предприятий к продакшену именно инфраструктурные решения определяют их конкурентное положение.
Децентрализованное GPU-облако Aethir обеспечивает доступ к GPU на уровне bare metal при облачной экономике масштабов. Более 435 000 GPU-контейнеров в 200+ локациях позволяют Aethir предоставлять выделенную производительность аппаратного уровня с экономией до 86% по сравнению с крупными гиперскейлерами — без комиссий за вывод данных и с развертыванием за 24–48 часов.
Налог на виртуализацию: скрытое падение производительности
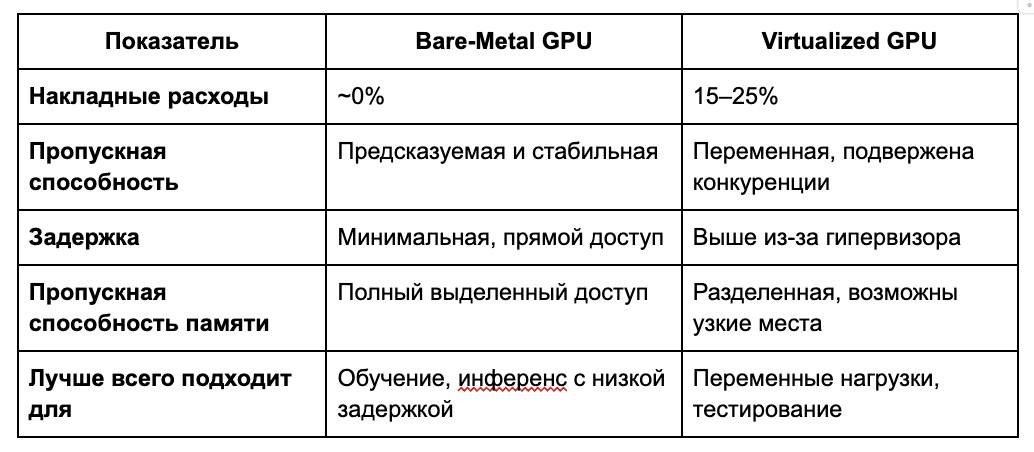
Виртуализация GPU распределяет физическое оборудование между несколькими пользователями, создавая значительные накладные расходы. Гипервизор добавляет нагрузку на CPU, создает конкуренцию за пропускную способность памяти, задержки ввода/вывода и эффект «шумных соседей».
Хотя исследования VMware показывают 4–5% накладных расходов в контролируемых условиях, реальные развертывания демонстрируют 15–25% падение производительности по сравнению с bare metal. Для AI-компаний это означает на 20% более медленное обучение, большие задержки при инференсе и соответственно увеличенные расходы. Эти различия резко усиливаются при многодневном обучении или высокопроизводительном инференсе, создавая то, что Aethir называет кризисом скрытых затрат в AI-инфраструктуре.
Bare Metal: производительность без компромиссов
Инфраструктура bare metal обеспечивает прямой доступ к GPU, устраняя накладные расходы виртуализации. Это гарантирует предсказуемую пропускную способность, максимальную ширину памяти (критично для инференса), нулевую конкуренцию за ресурсы и полный контроль над оборудованием.
Исследования показывают, что нагрузки инференса ограничены пропускной способностью памяти. Генерация 1 000 токенов/сек для модели 70B требует 140 ТБ/с пропускной способности — bare metal обеспечивает полный доступ без потерь на виртуализацию. Команда инфраструктуры Character.AI сообщает о 13,5-кратном преимуществе по стоимости при использовании bare metal, а бенчмарки фиксируют до 30% более высокую производительность при обучении крупных моделей.
Сравнение производительности: цифры
GPU NVIDIA H200 обладает на 76% большей памятью и на 43% большей пропускной способностью, чем H100, а архитектура B200 Blackwell обеспечивает 2,2-кратное превосходство над H100. С таким мощным оборудованием устранение даже 5% накладных расходов на виртуализацию даёт значительные выгоды.
Когда производительность имеет решающее значение
Обучение AI: Bare Metal лидирует
Обучение крупных моделей требует непрерывных вычислений в течение дней или недель. Сходимость модели зависит от стабильной производительности — любое падение удлиняет процесс. Bare metal выигрывает, поскольку обучение использует GPU почти на 100%, и даже малые потери производительности здесь критичны.
AI-инференс: критический фактор
Для инференса с минимальной задержкой — автономные автомобили, высокочастотный трейдинг, выявление мошенничества — bare metal незаменим. Ответ в субмиллисекундных масштабах не оставляет места для виртуализационных потерь. Character.AI, обрабатывая 20 000 запросов/сек, использует bare metal для поддержания вовлечённости пользователей при контроле затрат. Это и есть так называемая революция инференса, где нагрузки на инференс получают колоссальные преимущества от пропускной способности bare metal.
Преимущество Aethir
Децентрализованное GPU-облако Aethir обеспечивает производительность bare metal без накладных расходов виртуализации, поддерживая NVIDIA H100, H200 и B200. Более 435 000 GPU-контейнеров в 200+ локациях позволяют Aethir соединять клиентов с ближайшими GPU для минимальной задержки.
Экономическая эффективность масштабируется экспоненциально. Aethir обеспечивает до 86% экономии по сравнению с традиционными облаками, предлагая H100 за $1,25/час и нулевые комиссии за вывод данных, устраняя скрытые издержки, которые часто превышают стоимость вычислений.
Развертывание соответствует гибкости облаков: если традиционные bare-metal-решения требуют недель, то Aethir выполняет это за 24–48 часов без долгосрочных обязательств.
Контроль качества гарантирует надежность: 91 000+ Checker Nodes мониторят все GPU-контейнеры, а децентрализованная архитектура обеспечивает резервирование по континентам. Этот подход представляет собой фундаментальный сдвиг в том, как компании воспринимают традиционный и децентрализованный облачный хостинг.
Производительность как конкурентное преимущество
По мере того как AI-нагрузки переходят в продакшен и обслуживают миллионы пользователей, требования к инфраструктуре становятся очевидны: производительность — это основа конкурентного преимущества. С 90% организаций, внедряющих generative AI, и 39% — уже в продакшене, ограничения виртуализации становятся неприемлемыми в масштабах.
Виртуализация подходит для разработки, но продакшен-AI требует предсказуемой производительности, которую может обеспечить только bare metal. Aethir демократизирует эту инфраструктуру, делая индустриальный уровень bare metal доступным для компаний любого размера.
Когда производительность имеет значение — bare metal побеждает, и именно эти компании определят следующую эпоху инноваций в AI.
Готовы испытать преимущество bare-metal GPU?Свяжитесь с Aethir, чтобы обсудить ваши инфраструктурные требования и узнать, как децентрализованное GPU-облако может ускорить ваши AI-проекты.




