
AI業界は、これまで以上に大規模なモデルをトレーニングする段階から、それらを大規模にデプロイ(展開)する段階へと移行しています。AI推論市場は2030年までに2,549億8,000万ドルに達すると予測されており、データセンター需要の70%はAI推論アプリケーションからもたらされると見られています。企業が本番環境へと移行するにつれ、インフラに関する決定が競争上の地位を左右するようになっています。
Aethirの分散型GPUクラウドは、クラウドスケールの経済性でベアメタルGPUアクセスを提供します。200以上の拠点にまたがる435,000以上のGPUコンテナにより、Aethirは専用ハードウェアのパフォーマンスを、主要なハイパースケーラーと比較して最大86%のコスト削減、加えてゼロ・エグレスフィー(データ転送料金ゼロ)、24〜48時間でのデプロイメントと共に提供します。
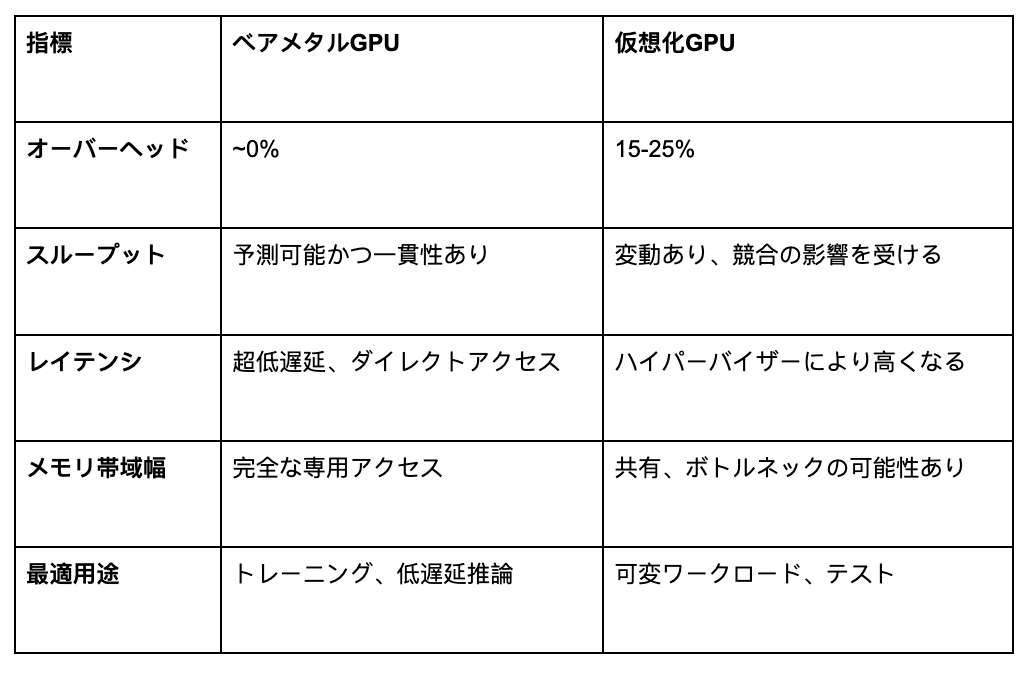
仮想化の税:隠れたパフォーマンスのペナルティ
GPUの仮想化は、物理ハードウェアを複数のテナント間で共有するため、重大なオーバーヘッド(間接的負荷)を引き起こします。ハイパーバイザー層は、CPUオーバーヘッド、メモリ帯域幅の競合、I/Oレイテンシ、そして「ノイジーネイバー」(同一ハードウェア上の他の高負荷ユーザーによる性能低下)の影響を追加します。
VMwareの調査では、管理された環境下でのオーバーヘッドは4〜5%と示されていますが、実世界のデプロイメントでは、ベアメタルと比較して15〜25%のパフォーマンス低下が発生します。大規模に展開するAI企業にとって、これは20%遅いトレーニング、より高い推論レイテンシ、そしてそれに比例したコスト増加を意味します。これらの差は、複数日にわたるトレーニングや高スループットの推論において劇的に積み重なり、Aethirが「AIインフラにおける隠れたコスト危機」と呼ぶ状況を生み出します。
ベアメタル:妥協のないパフォーマンス
ベアメタルインフラは、GPUへの直接アクセスを提供し、仮想化オーバーヘッドを排除します。これにより、予測可能なスループット、最大化されたメモリ帯域幅(推論にとって極めて重要)、リソース競合ゼロ、そして完全なハードウェア制御が実現します。
調査によれば、推論ワークロードはメモリ帯域幅律速(メモリ帯域幅によって性能が制限される)です。70B(700億)パラメータのモデルで毎秒1,000トークンを生成するには140 TB/sの帯域幅が必要であり、ベアメタルは仮想化オーバーヘッドなしに完全なアクセスを提供します。Character.AIのインフラチームは、ベアメタルによって13.5倍のコスト優位性があったと報告しており、ベンチマークによれば、大規模モデルのトレーニングにおいて最大30%高いパフォーマンスが示されています。
パフォーマンス比較:数値
NVIDIAのH200はH100よりも76%多いメモリと43%高い帯域幅を特徴とし、B200 BlackwellアーキテクチャはH100の2.2倍のパフォーマンスを提供します。このような強力なハードウェアでは、わずか5%の仮想化オーバーヘッドを排除するだけでも、大幅なゲイン(利得)が生まれます。
パフォーマンスが最も重要となる場面
AIトレーニング:ベアメタルの圧勝
大規模モデルのトレーニングには、数日から数週間にわたる持続的なコンピュート(計算資源)が必要です。モデルの収束には中断のないパフォーマンスが要求され、わずかな性能低下もトレーニング時間を延長させます。ベアメタルが優れているのは、トレーニングがGPU使用率をほぼ100%まで最大化する分野であり、そこではわずかなパーセンテージの違いが劇的に積み重なるからです。
AI推論:決定的な要因
自動運転車、高頻度取引、不正検知など、レイテンシ(遅延)が致命的となる推論において、ベアメタルは不可欠です。ミリ秒未満の応答時間が求められるため、仮想化オーバーヘッドの余地はありません。毎秒20,000クエリを処理するCharacter.AIは、コストを制御しながらエンゲージメントを維持するためにベアメタルに依存しています。これは、多くの人々が「推論革命」と呼ぶ現象を表しており、推論ワークロードはベアメタルの帯域幅の利点から莫大な恩恵を受けます。
Aethirの優位性
Aethirの分散型GPUクラウドは、仮想化オーバーヘッドなしのベアメタル性能を提供し、NVIDIAのH100、H200、B200 GPUをサポートしています。200以上の拠点にわたる435,000以上のGPUコンテナにより、Aethirはクライアントを近接するGPUとペアリングし、レイテンシを最小限に抑えます。
コスト効率は劇的に向上します。 Aethirは従来のクラウドと比較して最大86%の節約を提供し、H100を1時間あたり$1.25で、かつエグレスフィーゼロで提供します。これにより、しばしばコンピュート費用を上回る隠れたコストを排除します。
デプロイメントはクラウドの俊敏性に匹敵します。 従来のベアメタルが数週間を要するのに対し、Aethirは長期契約なしで24〜48時間以内にデプロイします。
品質保証が信頼性を確保します。 91,000以上のチェッカーノードがすべてのGPUコンテナを監視し、分散型アーキテクチャが大陸をまたいだ冗長性を提供します。このアプローチは、企業が従来型クラウドホスティングと分散型クラウドホスティングについてどう考えるかにおいて、根本的な変化を意味します。
競争優位性としてのパフォーマンス
AIワークロードが成熟し、何百万人にもサービスを提供する本番システムへと移行するにつれて、インフラ要件は明確になっています。パフォーマンスは競争優位性の基盤です。90%の組織が生成AIをデプロイし、39%が本番環境にある今、仮想化によるパフォーマンスの制限は、大規模環境では維持不可能なものとなっています。
仮想化は開発ニーズには役立ちますが、本番AIにはベアメタルだけが提供できる予測可能なパフォーマンスが要求されます。Aethirはこのインフラを民主化し、あらゆる段階の企業がエンタープライズグレードのベアメタルを利用できるようにします。パフォーマンスが重要な場面では、ベアメタルが勝利します。そして、このことを認識した企業が、AIイノベーションの次の時代を定義するでしょう。
ベアメタルGPUのパフォーマンス上の優位性を体験する準備はできましたか? Aethirにご連絡いただき、貴社のインフラ要件についてご相談ください。分散型GPUクラウドが貴社のAIイニシアチブをいかに加速できるかをご覧ください。




