
Industri AI telah bergeser dari sekadar melatih model berukuran besar ke tahap penerapan dalam skala luas. Pasar Inferensi AI diproyeksikan mencapai $254,98 miliar pada tahun 2030, dengan 70% permintaan pusat data berasal dari aplikasi inferensi AI. Saat perusahaan memasuki fase produksi, keputusan terkait infrastruktur akan menentukan posisi kompetitif mereka.
GPU cloud terdesentralisasi milik Aethir menyediakan akses GPU bare-metal dengan skala ekonomi setara cloud. Dengan lebih dari 435.000 Kontainer GPU di 200+ lokasi, Aethir menghadirkan performa perangkat keras khusus dengan penghematan biaya hingga 86% dibandingkan hyperscaler besar—tanpa biaya egress dan waktu penyebaran hanya 24-48 jam.
Pajak Virtualisasi: Penalti Performa yang Tersembunyi
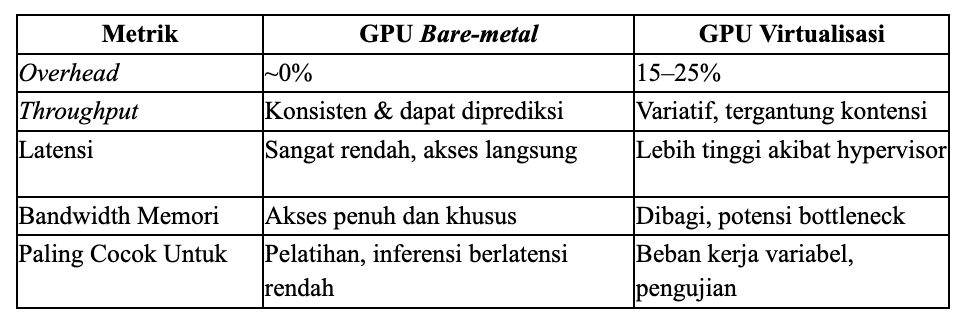
Virtualisasi GPU membagi perangkat keras fisik di antara banyak penyewa, sehingga menimbulkan overhead yang signifikan. Lapisan hypervisor menambah beban CPU, menyebabkan perebutan bandwidth memori, latensi I/O, serta efek “noisy neighbor”.
Meskipun riset VMware menunjukkan overhead 4-5% di lingkungan terkendali, penerapan di dunia nyata mengalami penalti performa 15-25% dibandingkan bare-metal. Bagi perusahaan AI dalam skala besar, ini berarti pelatihan 20% lebih lambat, latensi inferensi lebih tinggi, dan peningkatan biaya yang sebanding. Perbedaan ini akan terakumulasi secara signifikan untuk pelatihan multi-hari atau inferensi ber-throughput tinggi, menciptakan apa yang disebut Aethir sebagai krisis biaya tersembunyi dalam infrastruktur AI.
Bare metal: Performa Tanpa Kompromi
Infrastruktur bare-metal memberikan akses langsung ke GPU, menghilangkan overhead dari virtualisasi. Hal ini menghasilkan throughput yang konsisten, bandwidth memori maksimal (penting untuk inferensi), tanpa kompetisi sumber daya, dan kontrol penuh terhadap perangkat keras.
Riset menunjukkan bahwa beban kerja inferensi sangat bergantung pada bandwidth memori. Menghasilkan 1.000 token/detik untuk model 70B membutuhkan bandwidth 140 TB/detik—dan bare-metal memberikan akses penuh tanpa hambatan virtualisasi. Tim infrastruktur Character.AI melaporkan keunggulan biaya 13,5X dengan bare-metal, sementara benchmark menunjukkan peningkatan performa hingga 30% untuk pelatihan model besar.
Perbandingan Performa: Data Nyata
NVIDIA H200 memiliki 76% lebih banyak memori dan 43% bandwidth lebih tinggi dibanding H100, sementara arsitektur Blackwell B200 menghadirkan performa 2,2X lebih tinggi dari H100. Dengan perangkat keras sekuat ini, menghilangkan overhead virtualisasi sekecil 5% saja sudah dapat memberikan keuntungan besar.
Saat Performa Jadi Kunci Utama
Pelatihan AI: Bare metal Mendominasi
Melatih model besar membutuhkan komputasi berkelanjutan selama berhari-hari atau berminggu-minggu. Konvergensi model menuntut performa tanpa gangguan—setiap degradasi memperpanjang waktu pelatihan. Bare-metal unggul karena pelatihan memanfaatkan GPU hingga mendekati 100%, di mana perbedaan kecil dalam performa dapat berdampak besar.
Inferensi AI: Faktor Kritis
Untuk inferensi berlatensi sangat rendah—seperti kendaraan otonom, perdagangan frekuensi tinggi, dan deteksi penipuan—bare-metal menjadi keharusan. Waktu respons dalam sub-milidetik tidak memberi ruang untuk overhead virtualisasi. Character.AI, yang menangani 20.000 permintaan per detik, bergantung pada bare-metal untuk menjaga keterlibatan pengguna sambil mengontrol biaya. Fenomena ini dikenal sebagai revolusi inferensi, di mana beban kerja inferensi memperoleh keuntungan besar dari keunggulan bandwidth bare-metal.
Keunggulan Aethir
GPU cloud terdesentralisasi Aethir menghadirkan performa bare-metal tanpa overhead virtualisasi, mendukung GPU NVIDIA H100, H200, dan B200. Dengan lebih dari 435.000+ Kontainer GPU di 200+ lokasi, Aethir memasangkan klien dengan GPU terdekat untuk latensi minimal. Efisiensi biaya meningkat drastis. Aethir memberikan penghematan hingga 86% dibandingkan cloud tradisional, dengan H100 seharga $1,25/jam dan tanpa biaya egress—menghilangkan biaya tersembunyi yang sering kali lebih besar dari biaya komputasi itu sendiri.
Penerapan juga sama gesitnya dengan cloud. Jika bare-metal tradisional membutuhkan waktu berminggu-minggu, Aethir dapat menyebarkan dalam 24–48 jam tanpa komitmen jangka panjang.
Kualitas dijamin dengan keandalan tinggi. Lebih dari 91.000+ Checker Nodes memantau seluruh Kontainer GPU, sementara arsitektur terdesentralisasi menyediakan redundansi lintas benua. Pendekatan ini menandai perubahan mendasar dalam cara perusahaan memandang cloud hosting tradisional vs. terdesentralisasi.
Performa Sebagai Keunggulan Kompetitif
Seiring beban kerja AI berkembang menjadi sistem produksi yang melayani jutaan pengguna, kebutuhan infrastruktur menjadi jelas: performa adalah fondasi keunggulan kompetitif. Dengan 90% organisasi menerapkan generative AIdan 39% sudah dalam tahap produksi, keterbatasan performa dari virtualisasi menjadi tidak dapat diterima dalam skala besar.
Virtualisasi memang berguna untuk tahap pengembangan, tetapi produksi AI membutuhkan performa yang hanya dapat diberikan oleh bare-metal. Aethir mendemokratisasi infrastruktur ini, membuat bare-metal kelas enterprise dapat diakses oleh perusahaan di berbagai tahap pertumbuhan. Ketika performa menjadi segalanya, bare-metal adalah pemenangnya—dan perusahaan yang menyadari hal ini akan menjadi penentu arah era inovasi AI berikutnya.
Siap merasakan keunggulan performa GPU bare-metal?Hubungi Aethir untuk mendiskusikan kebutuhan infrastruktur Anda dan temukan bagaimana GPU cloud terdesentralisasi dapat mempercepat inisiatif AI Anda.




