
Die neue Ära der KI-Infrastruktur
Die KI-Branche hat sich von der Entwicklung immer größerer Modelle zur massiven Bereitstellung im Echtbetrieb verschoben.
Der Markt für KI-Inferenz wird bis 2030 auf 254,98 Milliarden USD anwachsen – mit 70 % der Rechenzentrumsnachfrage durch Inferenz-Anwendungen.
Wenn Unternehmen in die Produktionsphase übergehen, werden Infrastrukturentscheidungen zu strategischen Wettbewerbsfaktoren.
Aethir’s dezentrale GPU-Cloud bietet Bare-Metal-GPU-Zugriff mit Cloud-ähnlicher Skalierbarkeit und Wirtschaftlichkeit:
Über 435.000 GPU-Container an mehr als 200 Standorten liefern dedizierte Hardwareleistung mit bis zu 86 % Kostenersparnis gegenüber großen Hyperscalern – ohne Egress-Gebühren und mit 24–48 Stunden Bereitstellung.
Die Virtualisierungssteuer: Der versteckte Performanceverlust
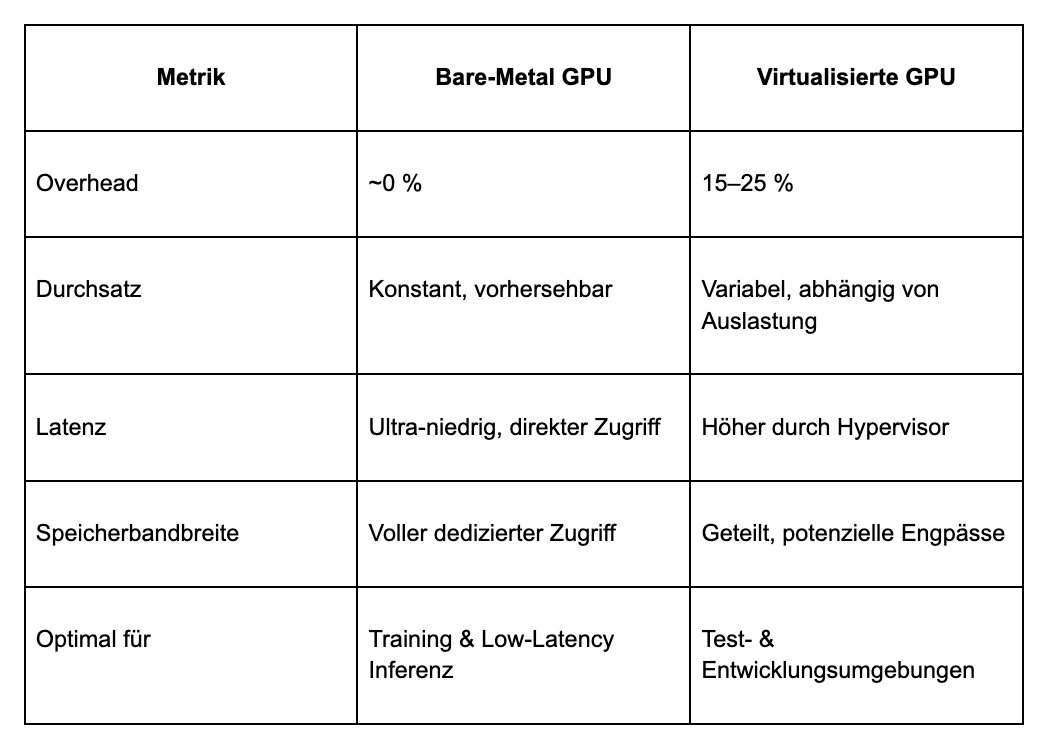
GPU-Virtualisierung teilt physische Hardware unter mehreren Nutzern auf – mit erheblichem Overhead.
Die Hypervisor-Schicht verursacht zusätzliche CPU-Last, Speicherbandbreitenkonkurrenz, I/O-Latenzen und „Noisy Neighbor“-Effekte.
Während VMware-Studien in Laborumgebungen nur 4–5 % Overhead zeigen, liegt der Leistungsverlust in der Praxis oft bei 15–25 % gegenüber Bare-Metal-Systemen.
Für KI-Unternehmen im Produktionsmaßstab bedeutet das:
- Bis zu 20 % längere Trainingszeiten
- Höhere Inferenzlatenzen
- Deutlich steigende Gesamtkosten
Diese Unterschiede summieren sich exponentiell bei tagelangen Trainings oder hochfrequenten Inferenzvorgängen – was Aethir als die „Hidden Cost Crisis“ der KI-Infrastruktur bezeichnet.
Bare Metal: Kompromisslose Leistung
Bare-Metal-Infrastruktur bietet direkten GPU-Zugriff, ohne Virtualisierungsschicht – und damit:
- Vorhersehbare Durchsatzraten
- Maximierte Speicherbandbreite (entscheidend für Inferenz)
- Keine Ressourcenkonkurrenz
- Volle Hardwarekontrolle
Untersuchungen zeigen: Inferenz-Workloads sind speicherbandbreitenlimitiert.
Um z. B. 1.000 Tokens/Sekunde bei einem 70B-Modell zu generieren, werden 140 TB/s Bandbreite benötigt – etwas, das nur Bare-Metal vollständig leisten kann.
Das Infrastrukturteam von Character.AI berichtet von einem 13,5-fachen Kostenvorteil mit Bare-Metal, während Benchmarks bis zu 30 % höhere Trainingsleistung gegenüber virtualisierten GPUs zeigen.
Leistungsvergleich: Die Zahlen
Die neue NVIDIA H200 bietet 76 % mehr Speicher und 43 % höhere Bandbreite als die H100, während die B200 Blackwell-Architektur 2,2× mehr Leistung liefert.
Selbst ein 5 %iger Virtualisierungs-Overhead verursacht bei solch starker Hardware massive Effizienzverluste.
Wenn Leistung entscheidend ist
KI-Training: Bare Metal dominiert
Das Training großer Modelle erfordert über Tage oder Wochen kontinuierliche Rechenleistung.
Modelle benötigen konstante Performance für Konvergenz – jede Verlangsamung verlängert die Trainingszeit.
Bare-Metal ist hier unschlagbar, da es GPU-Auslastung nahe 100 % erlaubt, wo selbst kleine Unterschiede enorme Auswirkungen haben.
KI-Inferenz: Der kritische Faktor
Bei Latenz-sensitiven Anwendungen – etwa in autonomen Fahrzeugen, Hochfrequenzhandel oder Betrugserkennung – ist Bare-Metal unverzichtbar.
Antwortzeiten im Millisekundenbereich lassen keinen Raum für Virtualisierungs-Overhead.
Beispiel: Character.AI, das 20.000 Anfragen pro Sekunde verarbeitet, nutzt Bare-Metal, um Engagement und Kostenkontrolle gleichzeitig zu gewährleisten.
Dies gilt als Teil der „Inference Revolution“, bei der Inferenz-Workloads massiv von Bare-Metal-Bandbreite profitieren.
Der Aethir-Vorteil
Aethirs dezentrale GPU-Cloud kombiniert Bare-Metal-Leistung mit Cloud-Flexibilität – ohne Virtualisierungsoverhead.
Unterstützt werden modernste GPUs:
- NVIDIA H100, H200 und B200
- 435.000+ GPU-Container in über 200 Standorten weltweit
Aethir verbindet Kunden automatisch mit nahegelegenen GPUs, um Latenzen zu minimieren.
Kosteneffizienz
- Bis zu 86 % günstiger als herkömmliche Cloud-Anbieter
- H100-GPUs ab 1,25 USD/Stunde
- Keine Egress-Gebühren – keine versteckten Zusatzkosten
Bereitstellungsgeschwindigkeit
- 24–48 Stunden Deployment, ohne langfristige Bindung
- Gleiche Agilität wie Cloud, aber mit dedizierter Hardwareperformance
Qualität & Zuverlässigkeit
- Über 91.000 Checker Nodes überwachen alle GPU-Container
- Dezentrale Architektur garantiert Ausfallsicherheit über Kontinente hinweg
Dieses Modell markiert einen fundamentalen Wandel darin, wie Unternehmen Cloud-Hosting und Compute-Resilienz denken.
Performance als Wettbewerbsvorteil
Da KI-Workloads zunehmend produktionsreif werden, ist eines klar:
Leistung ist der entscheidende Wettbewerbsvorteil.
Mit 90 % der Unternehmen, die generative KI implementieren, und 39 % bereits in Produktion, wird die Leistungsgrenze von Virtualisierung untragbar.
Virtualisierung eignet sich für Entwicklung und Tests – doch Produktions-KI erfordert die vorhersehbare Leistung von Bare-Metal-Systemen.
Aethir demokratisiert diese Infrastruktur:
Bare-Metal auf Enterprise-Niveau wird für Unternehmen jeder Größe zugänglich.
Wenn Leistung zählt, gewinnt Bare-Metal –
und die Unternehmen, die das erkennen, werden die nächste Ära der KI-Innovation prägen.
Bereit für echte Bare-Metal-Performance?
Kontaktiere Aethir, um über deine Infrastruktur-Anforderungen zu sprechen und zu erfahren,
wie eine dezentrale GPU-Cloud deine KI-Projekte beschleunigen kann.




