.jpg)
As artificial intelligence and AI-powered applications grow year-on-year, internet privacy becomes increasingly important. But by integrating with privacy technology like the Anyone Network - a decentralized onion routing network - users can build on AI securely and anonymously.
In this guest blog post by the Anyone Protocol team, we dive into how an Aethir decentralized GPU cloud unit can be configured to serve content anonymously, and evaluate its performance against existing GPU providers.
Let's dive in!
Executive Summary
Collaboration
Anyone collaborated with Aethir to evaluate its AI GPU cloud infrastructure, with an emphasis on GPU performance and scalability. The scope of this technical review is centered on bench marking GPU capabilities in AI workloads, complemented by the development of a practical AI powered utility bot deployed within the Telegram platform.
Before presenting the results, we begin with an overview comparing the infrastructure needs of a typical small-to-medium business (SMB) against the capabilities offered by a single Aethir GPU cloud unit. This sets the context for evaluating cost-effectiveness, scalability, and performance in real-world AI applications.
Architecture
Cloud Server Specifications
Model: RTX 5090×2
CPU: AMD Ryzen 9 7900X 12-Core Processor
RAM: 64 GiB
Storage: 2TB
Networking: 10Gb
GPU Power: 575W
Operating System: Ubuntu 22.04.1-Ubuntu
On-premise Server Specifications
Model: RTX 4090
CPU: 13th Gen Intel(R) Core(TM) i9-13900KS
RAM: 64 GiB
Storage: 2TB
Networking: 1Gb
GPU Power: 450W
Operating System: Kernel 6.17.2-arch1-1
Software Architecture
Both cloud and on-premise server configurations hold the same software configuration. The main difference is the GPU. The benchmark architecture has been defined as:
Front end: Telegram Bot (user interface)
Back end: python-telegram-bot integrated with ComfyUI
Database: PostgreSQL (state management and user-session tracking)
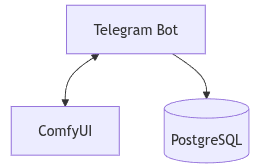
System Workflow
In our architecture, user interaction begins on Telegram, where the bot serves as the command interface. Each user query is parsed by the bot and translated into a task for ComfyUI, which performs the actual inference on the GPU.
The system functions as follows:
1. User sends a command via Telegram
2. Telegram bot (built using python-telegram-bot) receives and parses the command
3. The bot sends the task to ComfyUI for processing
4. ComfyUI performs inference using the appropriate model and returns an output (e.g., an image)
5. The output is sent back to the user via the Telegram chat
6. PostgreSQL is to manage user sessions, job queues, and the mapping between user commands and model wExample of bot command (/f for flux)orkflows.
This structure enables stateless inference with persistent context through the database, making it scalable and suitable for both single-user and multi-user scenarios.
Bot Example

Example of bot command (/f for flux)
This command sends a text-to-image prompt to ComfyUI. The bot processes the request, waits for the image to be generated, and sends back the result image directly in the Telegram chat to the user as shown in the result below.
Once an image has been generated (e.g., an astronaut, a t-shirt), users can build on it using additional commands. For instance, they can chain it with the “/qwen” command to ask to put the t-shirt on the astronaut:
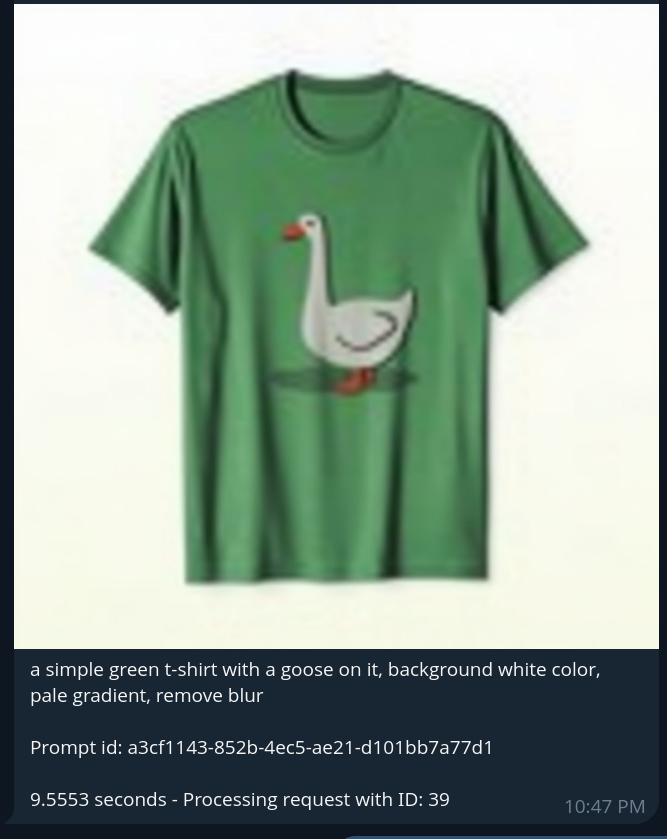

This invokes the Qwen model workflow, which performs image editing using a prior image as input along with a textual instruction. The resulting image is returned via Telegram with the modification applied (e.g., astronaut now wearing a goose t-shirt). This command chaining capability allows for interactive, multi-step image generation and editing all from within a lightweight chat interface.
Endpoints
All ComfyUI endpoints are exposed via routes and are documented in detail in the official server guide:
https://docs.comfy.org/development/comfyui-server/comms_routes
These endpoints form the backbone of communication between the back end and ComfyUI, enabling prompt submission, swift queue management, media upload and download, and real-time feedback.
Below are key endpoints relevant to our integration:
/ws websocket endpoint for real-time communication with the server
/upload /image post upload an image
/prompt get retrieve current queue status and execution information
/prompt post submit a prompt to the queue
/queue get retrieve the current state of the execution queue
/queue post manage queue operations (clear pending/running)
These endpoints are accessed programmatically through the back end, orchestrated by the Telegram bot to facilitate an interactive user experience without requiring users to directly engage with the API.
Privacy
To protect user data, ensure secure transmission and preserve privacy of the information, the ComfyUI endpoints are routed through the Anyone Network. This integration is made possible using the official Python SDK provided on the Anyone Protocol GitHub:
https://github.com/anyone-protocol/python-sdk
Using this development kit, we can wrap ComfyUI API calls within secure, anonymous tunnels ensuring that user queries and generated media are protected from unauthorized access or exposure.
Anyone Architecture wrapping endpoints with the binary called Anon:

In addition to encrypted tunneling, the Anyone SDK supports hidden services. Hidden services are private, ephemeral server endpoints that can run without revealing their location, identity, or IP. These are particularly valuable for use cases where discretion, censorship resistance, or enhanced security are critical. For operators, hidden services can enable GPU tasks to run privately, without exposing infrastructure details. Whether you're configuring inference pipelines anonymously, collaborating on sensitive data, or simply experimenting without leaving a trace, hidden services open up new possibilities for secure and sovereign compute.
A hidden service might look like this:
🌐 http://5ugakqk324gbzcsgql2opx67n5jisaqkc2mbglrodqprak5qz53mibyd.anon
🌐 http://5ugakqk324gbzcsgql2opx67n5jisaqkc2mbglrodqprak5qz53mibyd.anyone
Hidden services can be configured for the front end, assuming it’s a web platform in that case, or also for the ComfyUI back end endpoints, protecting the whole pipeline.
For more information on hidden services, we can look at the Anyone documentation:
https://docs.anyone.io/sdk-integrations/native-sdk/tutorials
Benchmarks
The following benchmarks compare the performance of the RTX 4090 and RTX 5090 across a range of ComfyUI workflows and models. All tests were conducted using consistent settings and templates to ensure fair comparison.
Stable Diffusion 3
ComfyUI Template: sd3.5_simple_example
4090: 8.96 seconds (average)
5090: 5.96 seconds (average)
Speedup = 33.48%
Workflow:
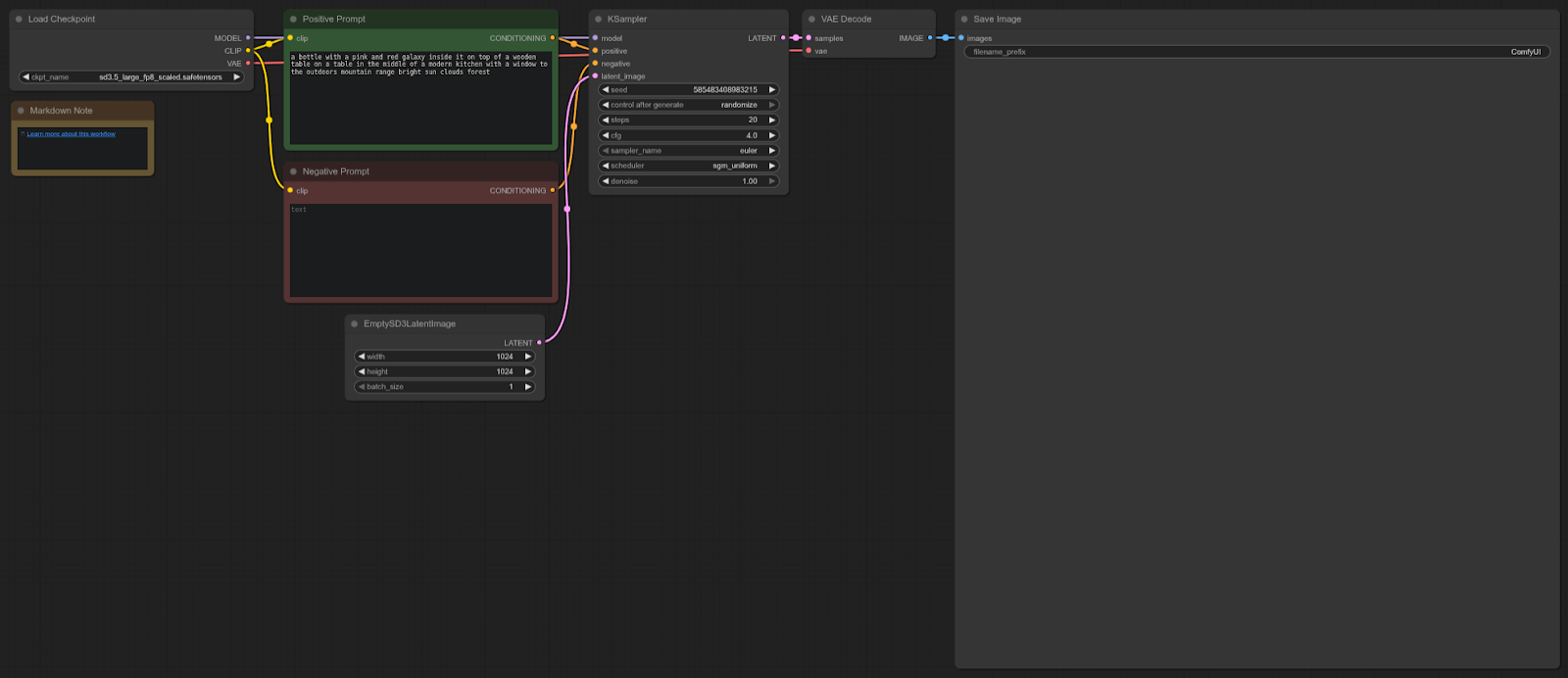
The RTX 5090 is ~33% faster than the 4090 in this test, offering a solid performance uplift for Stable Diffusion 3.5 workflows in ComfyUI.
FLUX-SCHNELL
ComfyUI Template: flux_schnell_full_text_to_image
4090: 4.92 seconds
5090: 1.80 seconds
Speedup = ~63.41%
Workflow:
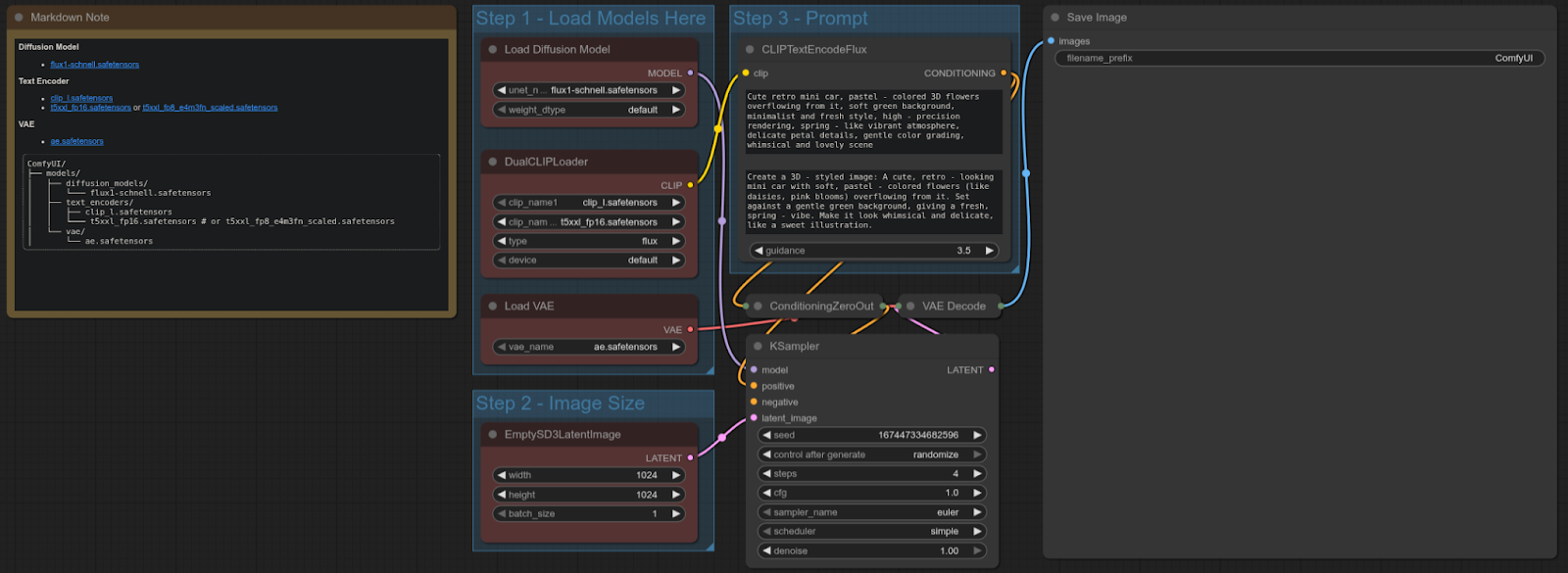
The RTX 5090 is ~63% faster than the 4090 in this test, providing a significant performance improvement for text-to-image workflows using the Flux Schnell model.
FLUX-DEV
ComfyUI Template: N/A (Custom Flux Dev Test Template)
4090: 16.05 seconds
5090: 10.11 seconds
Speedup = ~37.01%
Workflow:
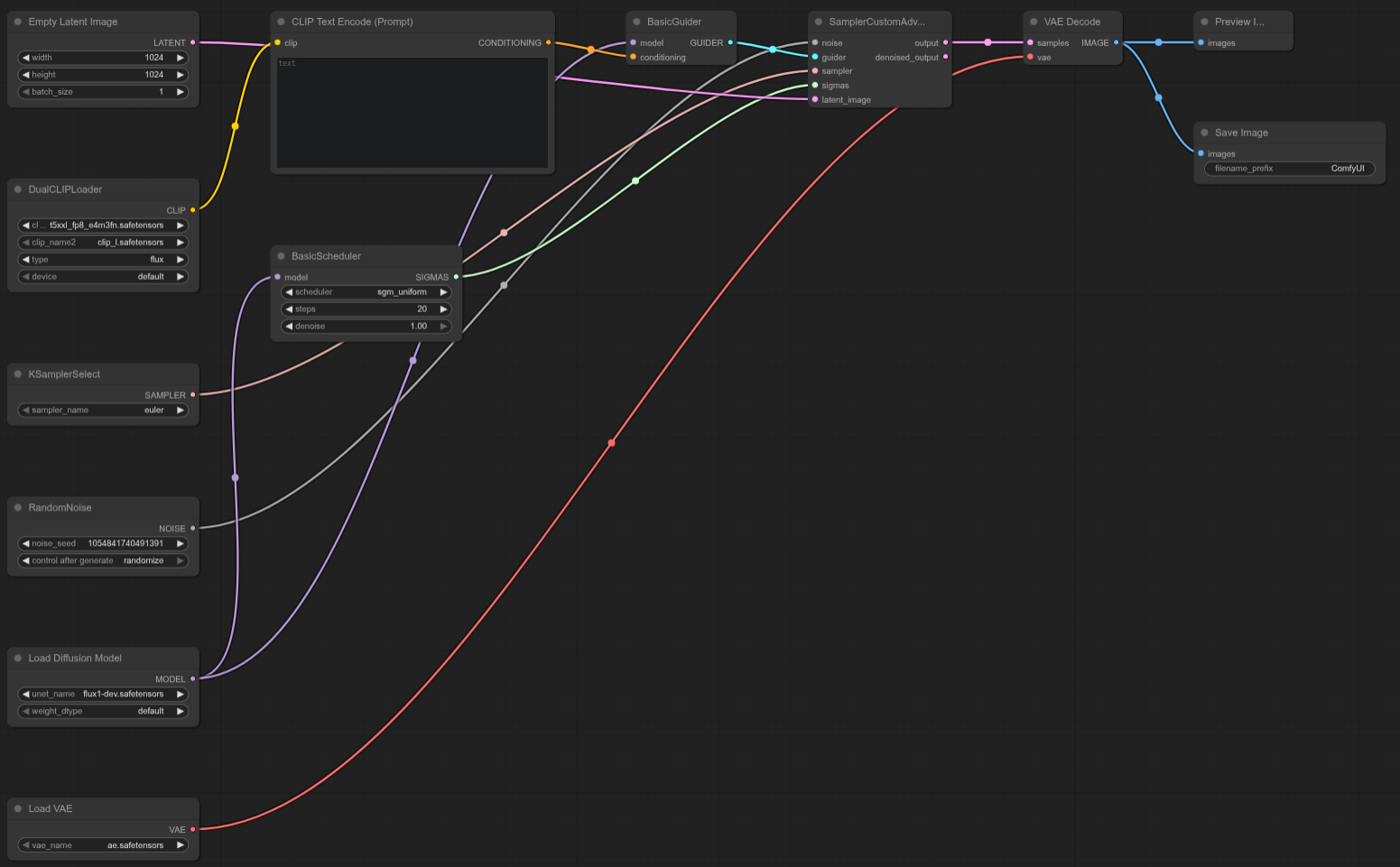
The RTX 5090 is ~37% faster than the 4090 in this custom Flux Dev test, delivering a strong boost in performance for this specific workflow.
WAN 2.2
ComfyUI Template: video_wan2_2_14B_t2v (fp8 scaled + 4 steps LoRA)
4090: 61.87 seconds
5090: 37.15 seconds
Speedup = ~39.94%
Workflow:
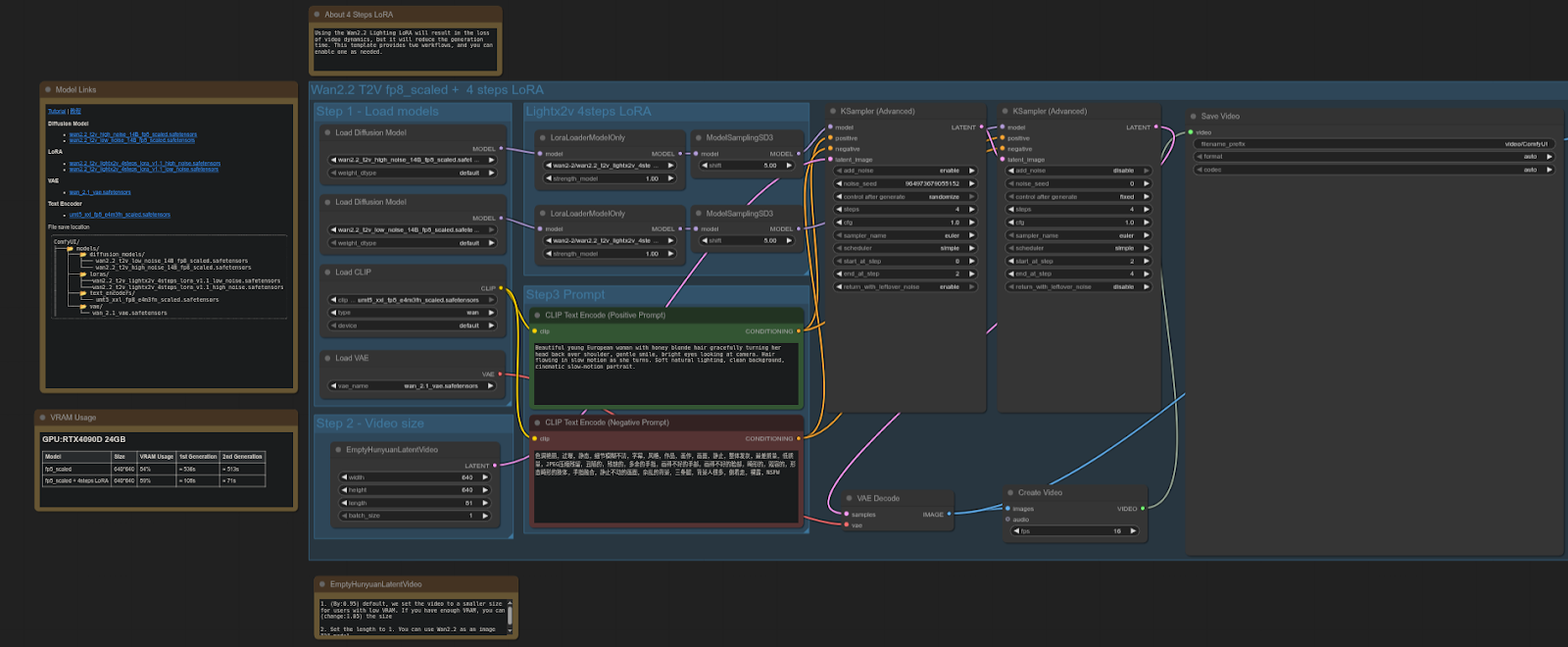
The RTX 5090 is ~40% faster than the 4090 in this test, a significant performance gain for video diffusion workflows using the FP8-scaled model + LoRA.
QWEN
ComfyUI Template: image_qwen_image_edit_2509
4090: 9.62 seconds
5090: 4.44 seconds
Speedup = ~53.83%
Workflow:
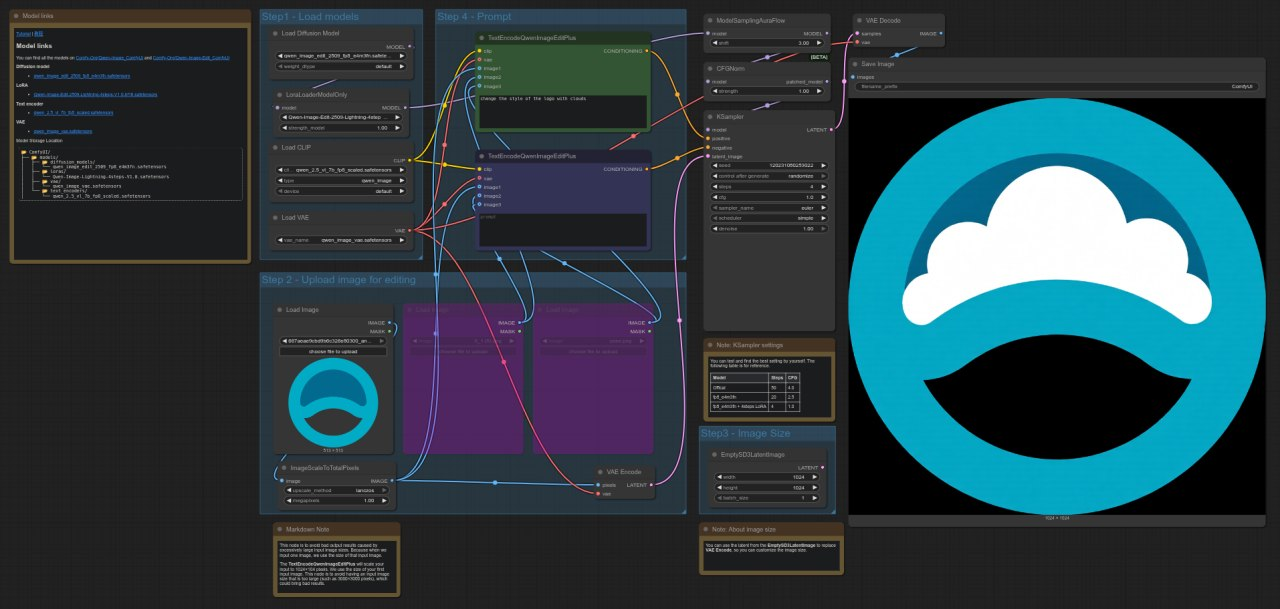
The RTX 5090 is ~54% faster than the 4090 in this test, showing a notable performance improvement for image editing workflows with the Qwen model.
Extra
Since the server is equipped with 2 GPUs, it is possible to programmatically distribute workloads between them. This can be achieved by defining specific CUDA devices for each node, allowing tasks to be split across both GPUs. The following repository demonstrates how to configure ComfyUI for multi-GPU setups by assigning nodes to different CUDA devices:
https://github.com/pollockjj/ComfyUI-MultiGPU

Short Introduction to the Anyone Protocol
Anyone is a decentralized global infrastructure for privacy. By integrating with their onion routing network, apps can provide trustless privacy and secure their network traffic without altering the user experience. The network consists of thousands of nodes that contribute bandwidth in exchange for token rewards. - https://www.anyone.io




