.jpg)
По мере того как искусственный интеллект и приложения на его основе растут из года в год, конфиденциальность в интернете становится всё более важной. Но благодаря интеграции с технологиями приватности, такими как Anyone Network — децентрализованная сеть маршрутизации на основе onion-технологии — пользователи могут создавать решения на базе ИИ безопасно и анонимно.
В этом гостевом блоге команды Anyone Protocol мы разбираем, как децентрализованный GPU-облачный модуль Aethir может быть настроен для анонимной подачи контента, и оцениваем его производительность по сравнению с существующими GPU-провайдерами.
Поехали!
Краткое содержание
Сотрудничество
Anyone сотрудничали с Aethir, чтобы оценить его AI GPU-облачную инфраструктуру, с акцентом на производительность и масштабируемость GPU. Объём технического обзора сосредоточен на бенчмаркинге возможностей GPU в AI-нагрузках, дополненных разработкой практического утилитарного бота на ИИ, развёрнутого в Telegram.
Прежде чем представить результаты, мы начинаем с обзора, сравнивающего инфраструктурные потребности типичного малого или среднего бизнеса (SMB) с возможностями, которые предоставляет один облачный GPU-модуль Aethir. Это задаёт контекст для оценки рентабельности, масштабируемости и производительности в реальных AI-приложениях.
Архитектура
Характеристики облачного сервера
Model: RTX 5090×2
CPU: AMD Ryzen 9 7900X 12-Core Processor
RAM: 64 GiB
Storage: 2TB
Networking: 10Gb
GPU Power: 575W
Operating System: Ubuntu 22.04.1-Ubuntu
Характеристики локального сервера
Model: RTX 4090
CPU: 13th Gen Intel(R) Core(TM) i9-13900KS
RAM: 64 GiB
Storage: 2TB
Networking: 1Gb
GPU Power: 450W
Operating System: Kernel 6.17.2-arch1-1
Программная архитектура
Обе конфигурации — облачная и локальная — используют одинаковую программную конфигурацию. Основное различие — GPU. Базовая архитектура бенчмарка определена следующим образом:
Front end: Telegram Bot (пользовательский интерфейс)
Back end: python-telegram-bot, интегрированный с ComfyUI
Database: PostgreSQL (управление состоянием и отслеживание пользовательских сессий)
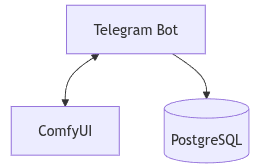
Рабочий процесс системы
В нашей архитектуре взаимодействие пользователя начинается в Telegram, где бот служит командным интерфейсом. Каждый пользовательский запрос парсится ботом и преобразуется в задачу для ComfyUI, который выполняет фактическое инференс-вычисление на GPU.
Система работает следующим образом:
- Пользователь отправляет команду через Telegram
- Telegram-бот (на python-telegram-bot) получает и парсит команду
- Бот отправляет задачу в ComfyUI для обработки
- ComfyUI выполняет инференс, используя соответствующую модель, и возвращает результат (например, изображение)
- Результат отправляется пользователю обратно в чат Telegram
- PostgreSQL управляет пользовательскими сессиями, очередями задач и соответствием между командами пользователей и рабочими процессами модели
Такая структура обеспечивает статлес-инференс с постоянным контекстом через базу данных, что делает систему масштабируемой и подходящей как для одного пользователя, так и для нескольких.
Пример работы бота

Пример команды бота (/f для flux)
Эта команда отправляет текст-в-изображение запрос в ComfyUI. Бот обрабатывает запрос, ожидает генерации изображения и отправляет результат напрямую пользователю в Telegram, как показано ниже.
После того как изображение создано (например, астронавт, футболка), пользователи могут продолжать работу над ним с помощью дополнительных команд. Например, они могут связать его с командой “/qwen”, чтобы попросить надеть футболку на астронавта:
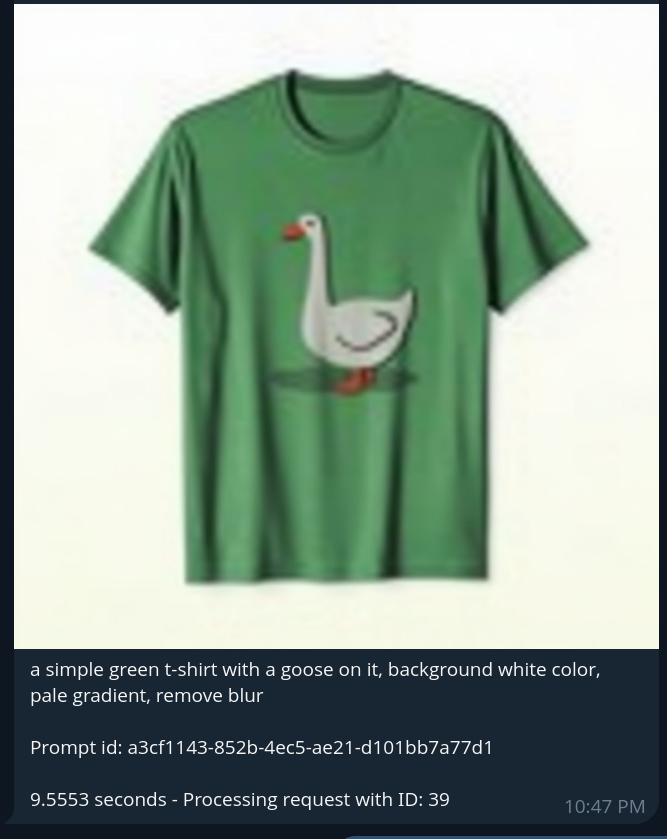

Это вызывает рабочий процесс модели Qwen, которая выполняет редактирование изображения, используя предыдущее изображение в качестве входных данных вместе с текстовой инструкцией. Итоговое изображение возвращается в Telegram с применённым изменением (например, астронавт теперь в футболке с гусём). Эта возможность связывать команды позволяет создавать интерактивную, многошаговую генерацию и обработку изображений в рамках лёгкого чат-интерфейса.
Эндпоинты
Все эндпоинты ComfyUI доступны через роуты и подробно задокументированы в официальном руководстве сервера:
https://docs.comfy.org/development/comfyui-server/comms_routes
Эти эндпоинты формируют основу взаимодействия между бэкендом и ComfyUI, обеспечивая отправку запросов, управление очередями, загрузку и скачивание медиа, а также обратную связь в реальном времени.
Ниже представлены ключевые эндпоинты, использованные в нашей интеграции:
Route
Type
Description
/ws
websocket
эндпоинт для обмена данными в реальном времени с сервером
/upload/image
post
загрузка изображения
/prompt
get
получение статуса очереди и информации о выполнении
/prompt
post
отправка prompt-запроса в очередь
/queue
get
получение текущего состояния очереди
/queue
post
управление операциями очереди (очистка pending/running)
Эти эндпоинты вызываются программно через бэкенд и управляются Telegram-ботом, обеспечивая интерактивный пользовательский опыт без необходимости взаимодействовать с API напрямую.
Конфиденциальность
Чтобы защитить данные пользователей, обеспечить безопасную передачу информации и сохранить приватность, эндпоинты ComfyUI маршрутизируются через Anyone Network. Эта интеграция реализуется с помощью официального Python SDK, доступного на GitHub Anyone Protocol:
https://github.com/anyone-protocol/python-sdk
Используя этот набор инструментов, мы можем оборачивать вызовы API ComfyUI в защищённые анонимные туннели, гарантируя, что пользовательские запросы и сгенерированные медиа защищены от несанкционированного доступа или утечки.
Архитектура Anyone, оборачивающая эндпоинты бинарем под названием Anon:

Помимо зашифрованных туннелей, Anyone SDK поддерживает скрытые сервисы (hidden services). Скрытые сервисы — это приватные, эфемерные серверные эндпоинты, которые могут работать без раскрытия своего местоположения, идентичности или IP. Они особенно полезны в сценариях, где критичны конфиденциальность, устойчивость к цензуре или повышенная безопасность.
Для операторов скрытые сервисы позволяют выполнять GPU-задачи приватно, не раскрывая детали инфраструктуры. Независимо от того, настраиваете ли вы инференс-пайплайн анонимно, работаете с чувствительными данными или просто экспериментируете без следов — скрытые сервисы открывают новые возможности для безопасных и суверенных вычислений.
Пример скрытого сервиса:
🌐 http://5ugakqk324gbzcsgql2opx67n5jisaqkc2mbglrodqprak5qz53mibyd.anon
🌐 http://5ugakqk324gbzcsgql2opx67n5jisaqkc2mbglrodqprak5qz53mibyd.anyone
Скрытые сервисы могут быть настроены как для фронтенда (если он представлен веб-платформой), так и для бэкенд-эндпоинтов ComfyUI, защищая весь пайплайн.
Для получения дополнительной информации о скрытых сервисах см. документацию Anyone:
https://docs.anyone.io/sdk-integrations/native-sdk/tutorials
Бенчмарки
Следующие бенчмарки сравнивают производительность RTX 4090 и RTX 5090 в различных рабочих процессах и моделях ComfyUI. Все тесты проводились с использованием единых настроек и шаблонов для обеспечения корректного сравнения.
Stable Diffusion 3
ComfyUI Template: sd3.5_simple_example
4090: 8.96 секунд (в среднем)
5090: 5.96 секунд (в среднем)
Ускорение = 33.48%
Workflow:
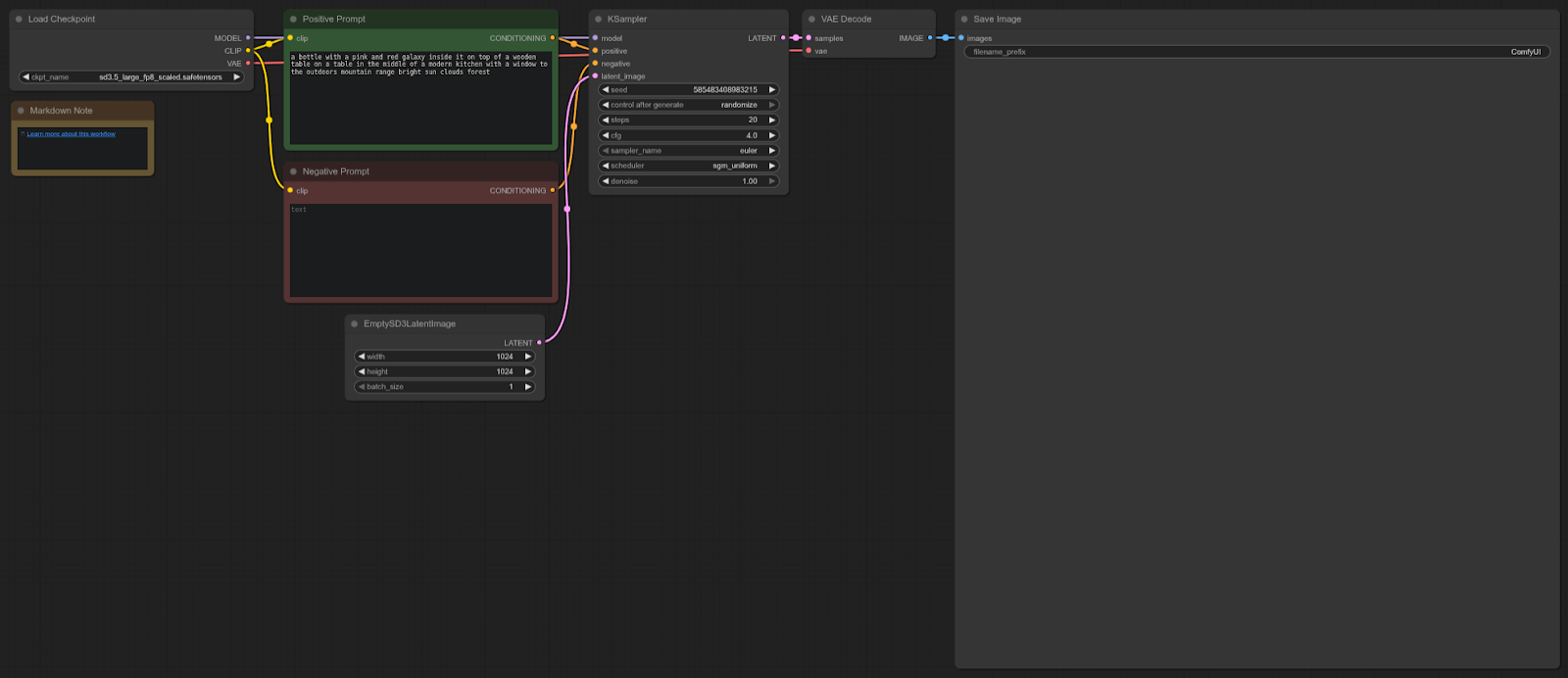
RTX 5090 примерно на ~33% быстрее, чем 4090 в этом тесте, обеспечивая существенный прирост производительности для рабочих процессов Stable Diffusion 3.5 в ComfyUI.
FLUX-SCHNELL
ComfyUI Template: flux_schnell_full_text_to_image
4090: 4.92 секунд
5090: 1.80 секунд
Ускорение = ~63.41%
Workflow:
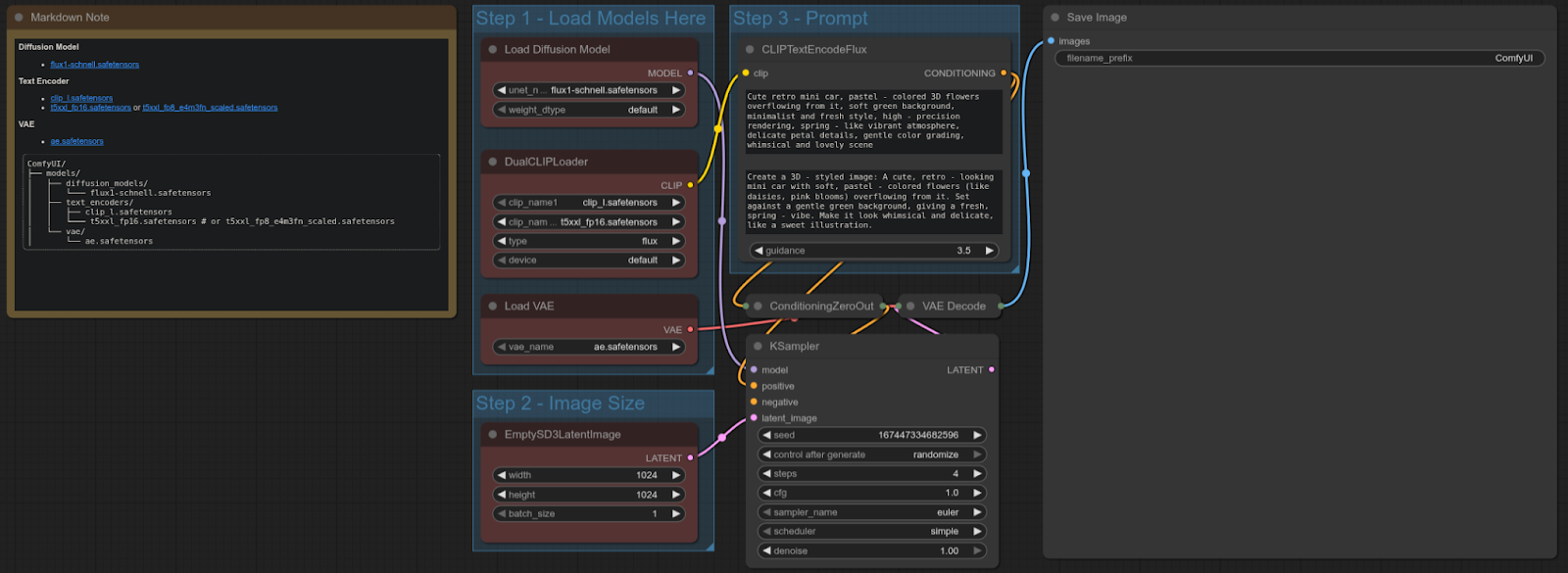
RTX 5090 примерно на ~63% быстрее, чем 4090 в этом тесте, обеспечивая значительное улучшение производительности для text-to-image рабочих процессов с использованием модели Flux Schnell.
FLUX-DEV
ComfyUI Template: N/A (Custom Flux Dev Test Template)
4090: 16.05 секунд
5090: 10.11 секунд
Ускорение = ~37.01%
Workflow:
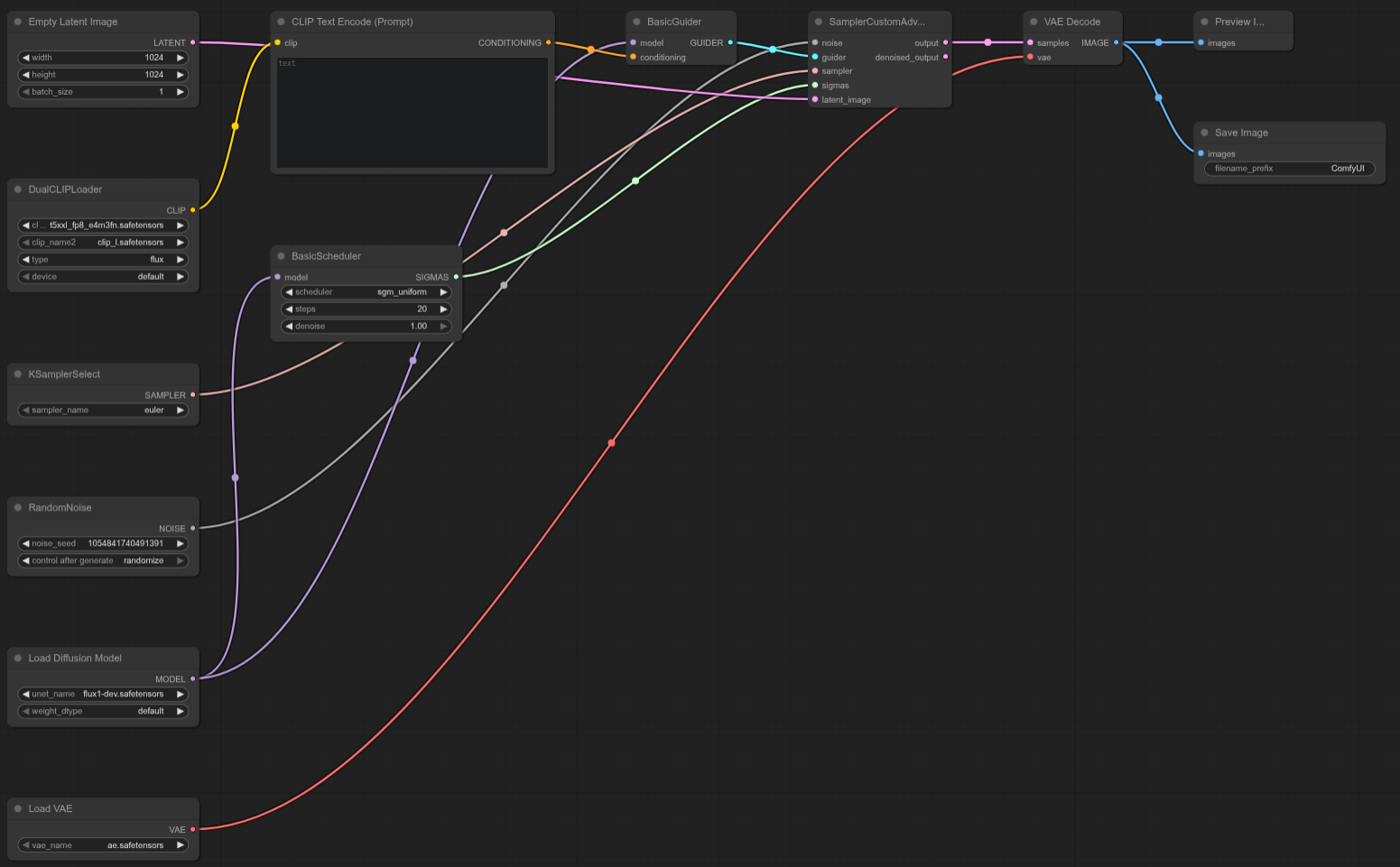
RTX 5090 примерно на ~37% быстрее, чем 4090 в этом кастомном Flux Dev тесте, обеспечивая мощный прирост производительности для данного рабочего процесса.
WAN 2.2
ComfyUI Template: video_wan2_2_14B_t2v (fp8 scaled + 4 steps LoRA)
4090: 61.87 секунд
5090: 37.15 секунд
Ускорение = ~39.94%
Workflow:
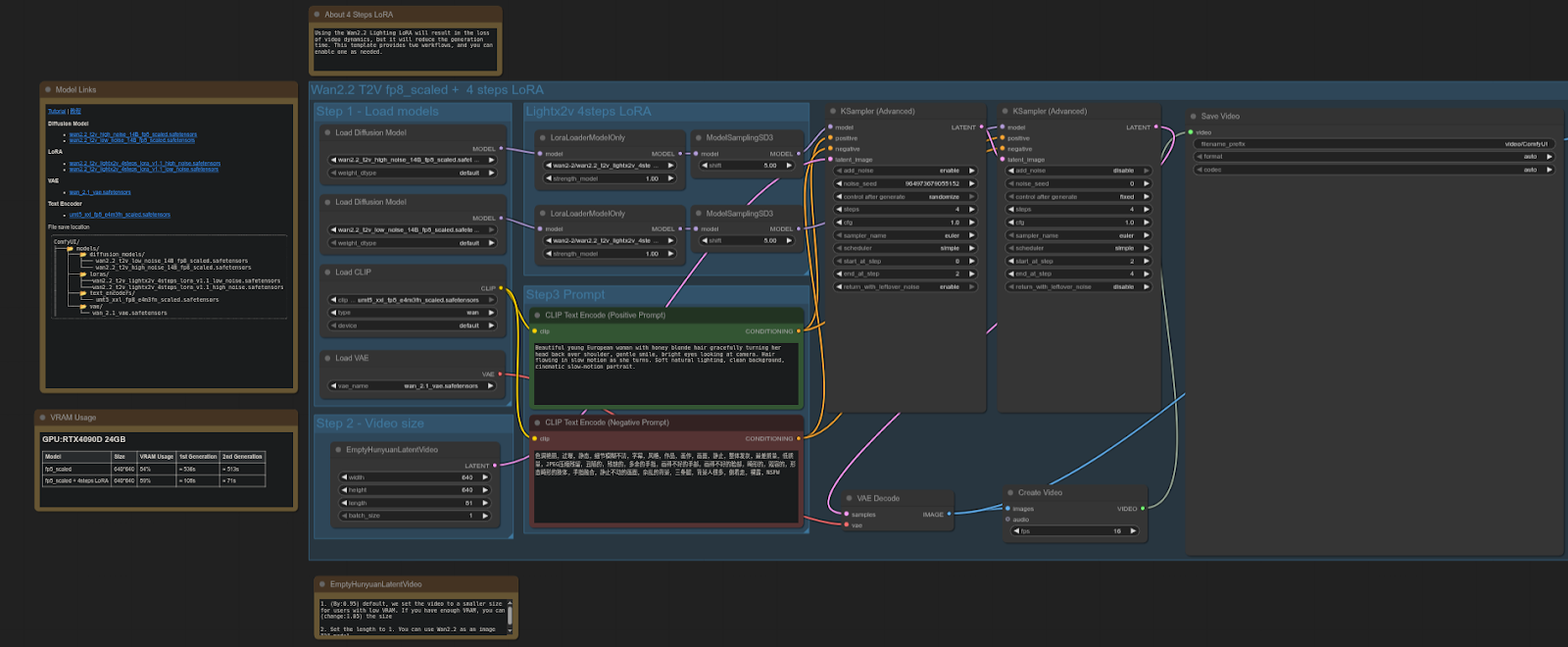
RTX 5090 примерно на ~40% быстрее, чем 4090 в этом тесте, что является существенным увеличением производительности для видео-диффузионных рабочих процессов с использованием FP8-скейлинга + LoRA.
QWEN
ComfyUI Template: image_qwen_image_edit_2509
4090: 9.62 секунд
5090: 4.44 секунд
Ускорение = ~53.83%
Workflow:
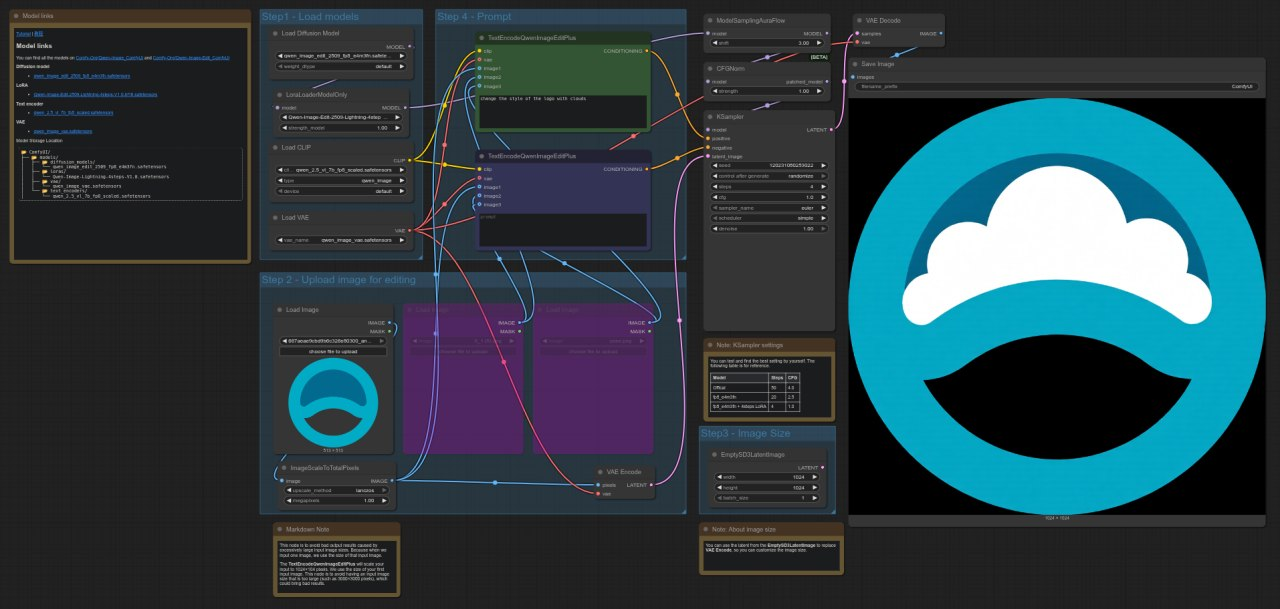
RTX 5090 примерно на ~54% быстрее, чем 4090 в этом тесте, демонстрируя заметное улучшение производительности для рабочих процессов редактирования изображений с моделью Qwen.
Extra
Так как сервер оснащён двумя GPU, существует возможность программно распределять рабочие нагрузки между ними. Это можно реализовать, задавая конкретные CUDA-устройства для каждого узла, что позволяет разделять задачи между обоими GPU. Следующий репозиторий демонстрирует, как настроить ComfyUI для работы с несколькими GPU, назначая узлы разным CUDA-устройствам:
https://github.com/pollockjj/ComfyUI-MultiGPU

Краткое введение в протокол Anyone
Anyone — это децентрализованная глобальная инфраструктура для приватности. Интегрируясь с их сетью onion routing, приложения могут обеспечивать доверенную приватность и защищать сетевой трафик без изменений пользовательского опыта. Сеть состоит из тысяч нод, которые предоставляют пропускную способность в обмен на токен-награды. — https://www.anyone.io




