
The Generative AI Revolution: Innovation Meets Infrastructure Limits
The generative AI revolution is no longer a distant forecast; it's a present-day reality reshaping industries from media and entertainment to scientific research. AI spending surged to over $13 billion in 2024, with generative AI attracting $33.9 billion globally in private investment—an 18.7% increase from 2023. However, this rapid advancement has also exposed a critical bottleneck: the inadequacy of current infrastructure to keep pace with the demands of large-scale AI workloads. Goldman Sachs projects that AI will cause power usage by data centers to increase by 160% by 2030, highlighting the infrastructure crisis facing the industry.
Traditional cloud solutions, once the go-to for scalable computing, are now revealing their limitations, creating significant hurdles for creative enterprises aiming to harness the full power of generative AI. The key to unlocking this potential lies in a return to the foundations of computing: bare-metal GPU infrastructure. Companies like Aethir are pioneering this shift toward decentralized, distributed computing networks, enabling organizations to access enterprise-grade performance without the traditional barriers of centralized cloud providers.
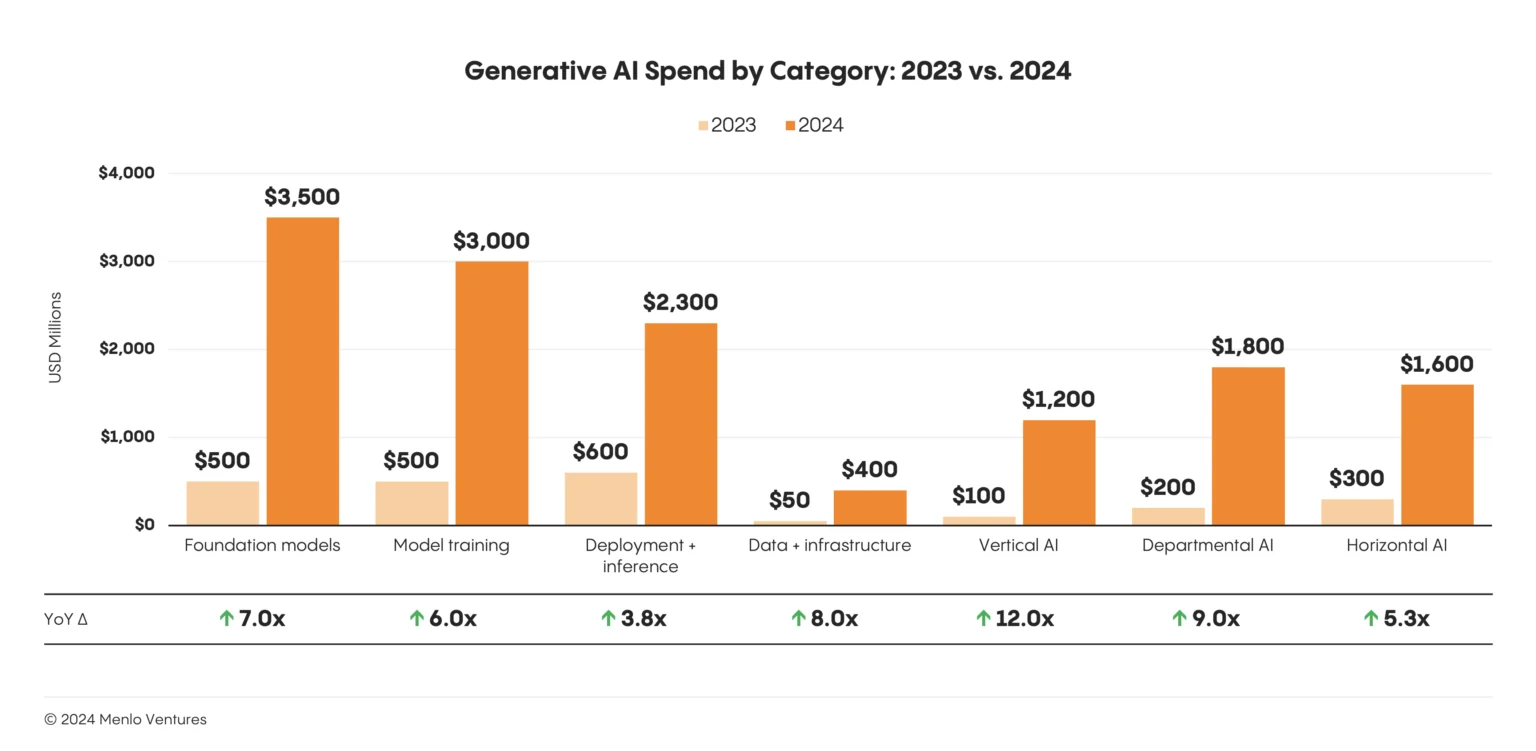
Source: Menlo Ventures
Cloud's Hidden Price Tag: Performance & Egress Fees
For years, virtualization has been the standard for cloud computing, promising flexibility and resource optimization. However, for the demanding requirements of generative AI, this abstraction layer introduces significant hidden costs and performance penalties. In contrast, bare-metal infrastructure providers like Aethir offer transparent, competitive pricing that eliminates these hidden costs entirely. The very nature of virtualization, which separates the physical hardware from the software, creates an inherent overhead that can throttle GPU performance by as much as 15-30%. This performance gap, which might be negligible for smaller tasks, becomes a critical issue for multi-day training jobs running on hundreds of GPUs, leading to substantial time and cost overruns.
Beyond the performance penalties, the economic model of traditional cloud services presents another significant challenge: the egress fee trap. AWS charges between $0.09-$0.05 per gigabyte for data egress after the first 100GB monthly free tier, and bandwidth charges for moving data out of the cloud can often exceed the cost of compute itself. This is particularly problematic for media companies working with high-resolution video, audio, and 3D assets. According to the Flexential 2024 State of AI Infrastructure Report, 42% of organizations have pulled AI workloads back from public cloud due to cost and privacy concerns. When combined with queue times and availability issues for high-demand GPUs, the true cost of traditional cloud solutions becomes a significant barrier to innovation.
Bare-Metal GPUs: The High-Performance Alternative
The move to bare-metal infrastructure is not just about cost savings; it's about unlocking the full performance potential of the underlying hardware. With transparent pricing models like those offered by Aethir, organizations can access this superior performance without the hidden costs and complexity of traditional solutions. By providing direct, unimpeded access to the GPU, bare-metal solutions eliminate the virtualization overhead that plagues traditional cloud environments. Recent studies show that GPU-accelerated VMs can reach 95-100% of bare-metal performance with optimized configurations, but most traditional cloud environments still suffer from significant performance penalties. This direct hardware access is critical for memory bandwidth optimization, a key factor in the performance of large model inference.
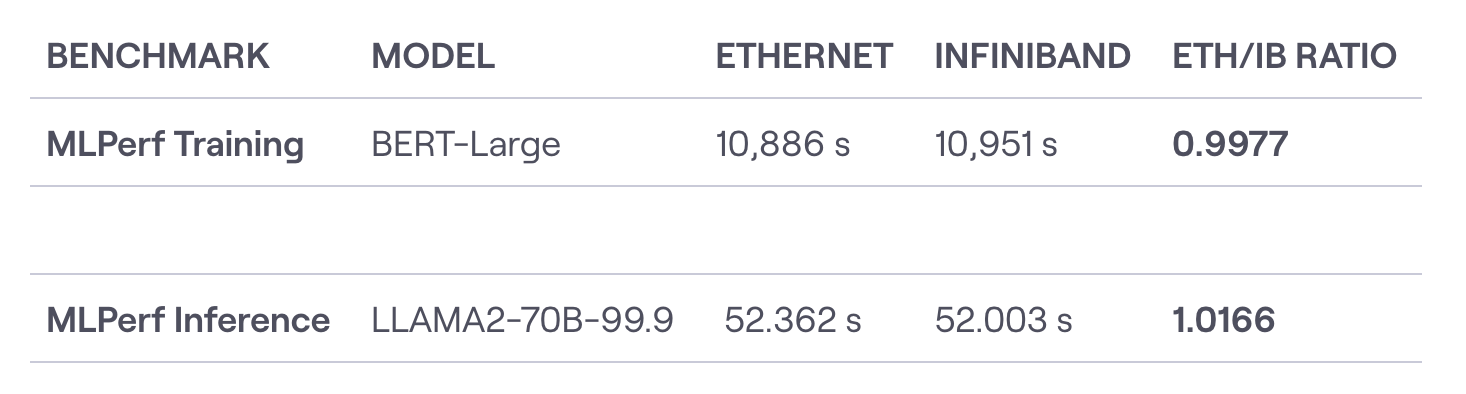
Source: WWT
Furthermore, the network fabric in a bare-metal environment plays a crucial role in the efficiency of distributed AI workloads. High-performance interconnects like InfiniBand offer significant advantages over standard Ethernet, with InfiniBand achieving average end-to-end latency of 1.2 microseconds compared to 1.9 microseconds for Ultra Ethernet in 128-node GPU clusters. The case of TensorOpera's Fox-1 LLM demonstrates the potential for significant cost reductions through optimized infrastructure, achieving competitive performance with substantially reduced resource requirements. By optimizing the entire stack, from the hardware to the network, companies can achieve significant performance gains and cost savings.
IV. AI Workloads Transformed with Bare-Metal Infrastructure
The benefits of bare-metal infrastructure are not limited to a single type of AI workload; they extend across the entire spectrum of generative AI applications.
A. Large Language Models (LLMs) For LLMs, bare-metal clusters offer significant efficiency gains in both training and inference. The ability to scale to thousands of GPUs in a high-performance, low-latency environment is critical for training the next generation of multi-modal models.
B. Image and Video Generation In the realm of media generation, bare-metal infrastructure enables real-time rendering capabilities and batch processing at scale. The high-bandwidth, low-cost storage and networking of bare-metal solutions are essential for managing the massive datasets involved in media workflows.
C. Audio and Music Generation The low-latency requirements of interactive audio and music generation applications are perfectly suited for bare-metal infrastructure. By eliminating the overhead of virtualization, developers can create more responsive and engaging user experiences.
D. 3D Content and Virtual Worlds For complex simulations and distributed rendering architectures, the GPU Direct capabilities of bare-metal solutions provide a significant performance advantage. This enables the creation of more realistic and immersive 3D content and virtual worlds.
V. Build vs. Rent: The New Economics of GPU Infrastructure
The decision to build or rent AI infrastructure is critical for any company. While building bare-metal clusters requires significant upfront investment, innovative decentralized infrastructure providers now offer a third option: accessing enterprise-grade bare-metal performance without capital expenditure or operational complexity. For example, purchasing a single H100 GPU can cost $25,000-$40,000, while an 8-GPU cluster setup requires $200,000+ in hardware alone—before factoring in networking, storage, and facility costs. In contrast, renting equivalent capacity through Aethir's platform for a full year costs significantly less while eliminating maintenance, power, and infrastructure management overhead.
Modern distributed computing platforms eliminate hidden costs by providing transparent pricing without egress fees or surprise bandwidth charges. ROI analysis consistently shows 40-80% cost reductions compared to traditional cloud providers, with break-even points typically occurring within 6-12 months for most workloads.
Technical Blueprint: Building a High-Performance AI Stack
Building a high-performance bare-metal AI cluster requires careful consideration of every component in the stack. The choice of GPU, from H100 to the latest B200 significantly impacts performance and cost. Network architecture decisions between InfiniBand, RoCE, and Ethernet are critical for distributed workloads. Storage solutions from providers like VAST, DDN, and WekaIO optimize AI workload performance. Cluster sizing ranges from 8-GPU development setups to 4,096-GPU superclusters.
Leading decentralized infrastructure providers like Aethir address these technical challenges by offering pre-optimized configurations across their global network of over 200 locations in 93 countries, ensuring organizations can access optimal configurations without infrastructure management complexity.
Migration Made Easy: Phased Strategies for Enterprise AI
Common migration concerns include business continuity, skills requirements, and performance validation. Successful organizations follow phased migration strategies: starting with non-critical workloads, validating performance benchmarks, then gradually migrating production systems. Key success factors include maintaining hybrid environments during transition, investing in team training, and establishing clear performance metrics.
Most organizations find that 24-48 hour deployment times and comprehensive technical support significantly reduce migration risks compared to traditional expectations.
The Future of AI Compute: Decentralized and Sustainable
The infrastructure landscape is rapidly evolving with emerging GPU technologies like NVIDIA's Blackwell B200 and GB200 architectures promising unprecedented performance gains. Decentralized infrastructure trends are accelerating, driven by sustainability concerns and the need for geographic distribution. Environmental considerations are becoming critical, with bare-metal solutions offering superior energy efficiency compared to virtualized alternatives.
Predictions for 2025-2027 include widespread adoption of decentralized GPU networks, integration of renewable energy sources, and the emergence of specialized AI infrastructure optimized for specific workload types.
Your Roadmap to High-Performance Generative AI l
Assessment Phase: Evaluate current infrastructure costs, identify performance bottlenecks, and quantify egress fees and hidden charges. Benchmark existing workloads to establish baseline performance metrics.
Pilot Program: Start with high-value, non-critical workloads that demonstrate clear ROI. Focus on applications with high bandwidth requirements or long-running training jobs where bare-metal advantages are most apparent.
Key Metrics: Track total cost of ownership, performance improvements, deployment speed, and operational efficiency. Monitor cost per GPU-hour, training time reduction, and infrastructure utilization rates.
Partnership Approach: Consider managed bare-metal services that provide enterprise-grade infrastructure without operational complexity, enabling focus on core AI development rather than infrastructure management.
Closing the Gap: Democratizing Generative AI with Aethir
Bare-metal GPU clusters, with superior performance, transparent pricing, and direct hardware access, are becoming the foundation for the next AI innovation wave. Decentralized platforms like Aethir are democratizing access to high-performance computing, enabling organizations of all sizes to compete equally in the AI-first economy through secure, cost-effective access to enterprise-grade GPUs across a global network.
The competitive imperative is clear: companies embracing bare-metal infrastructure through modern decentralized platforms will lead the generative everything revolution. The future belongs to those harnessing bare-metal GPU clusters' full power—and Aethir makes that future accessible to everyone.
Ready to transform your AI infrastructure? Contact Aethir's enterprise team today to discuss your specific requirements and discover how bare-metal GPU clusters can accelerate your generative AI initiatives enterprise.aethir.com to get started.




