
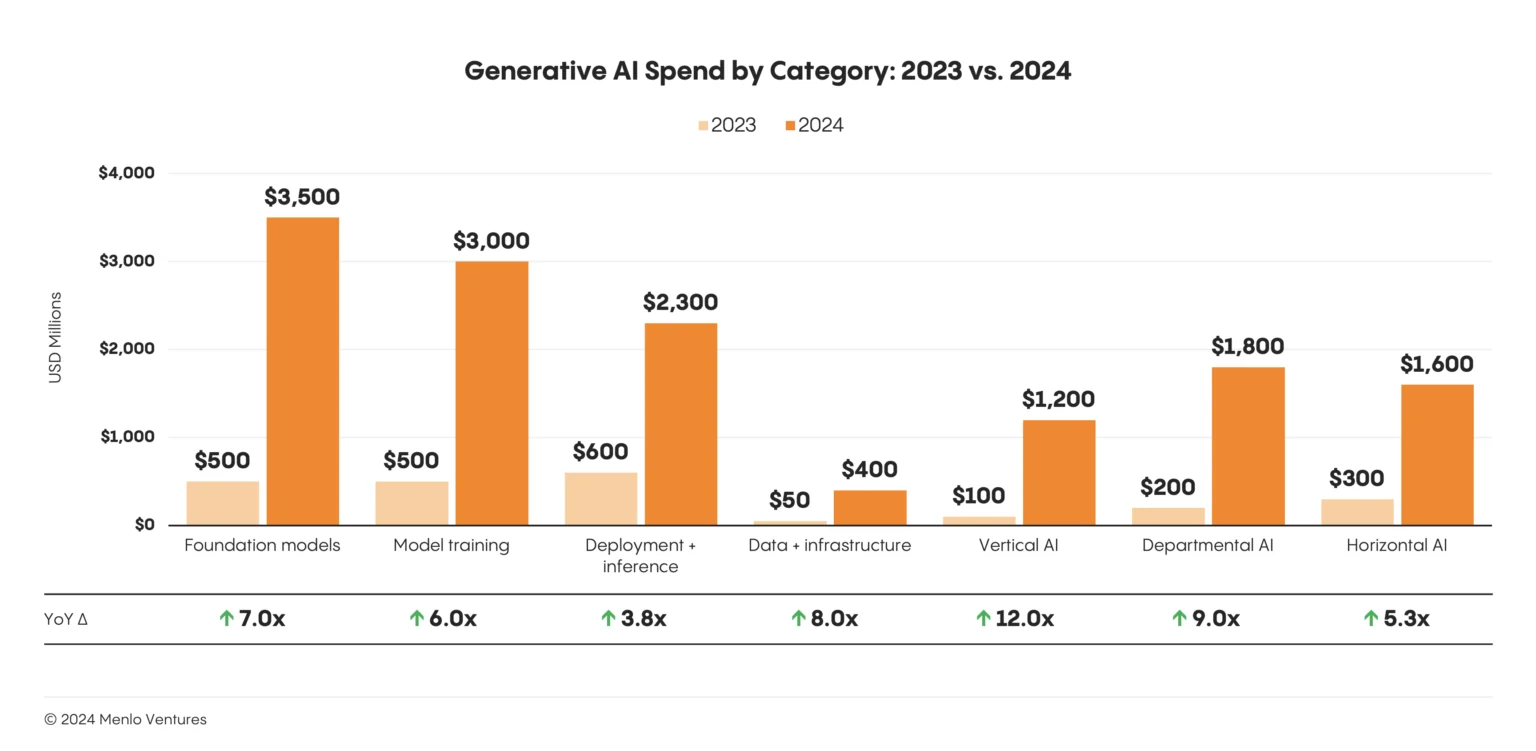
生成AI革命はもはや遠い未来の予測ではありません。メディアやエンターテイメントから科学研究に至るまで、産業を再形成している今日の現実です。AIへの支出は2024年に130億ドル以上に急増し、生成AIは全世界で339億ドルの民間投資を集めました。これは2023年から18.7%の増加です。しかし、この急速な進歩は、重大なボトルネックも露呈させました。それは、大規模なAIワークロードの要求に現在のインフラが追いついていないという問題です。ゴールドマン・サックスは、AIによってデータセンターの電力使用量が2030年までに160%増加すると予測しており、業界が直面しているインフラ危機を浮き彫りにしています。
かつてはスケーラブルなコンピューティングの頼みの綱であった従来のクラウドソリューションは、今やその限界を露呈し、生成AIの能力を最大限に活用しようとするクリエイティブ企業にとって大きな障壁となっています。この可能性を解き放つ鍵は、コンピューティングの基礎への回帰、すなわちベアメタルGPUインフラにあります。Aethirのような企業は、この分散型・分散コンピューティングネットワークへのシフトを開拓しており、組織が従来の集中型クラウドプロバイダーの障壁なしに、エンタープライズグレードのパフォーマンスにアクセスできるようにしています。
クラウドの隠れた価格:パフォーマンスとエグレス料金
長年、仮想化はクラウドコンピューティングの標準であり、柔軟性とリソースの最適化を約束してきました。しかし、生成AIの厳しい要件に対して、この抽象化レイヤーは重大な隠れたコストとパフォーマンスの低下をもたらします。対照的に、Aethirのようなベアメタルインフラプロバイダーは、これらの隠れたコストを完全に排除する、透明で競争力のある価格設定を提供します。物理的なハードウェアをソフトウェアから分離する仮想化の性質そのものが、GPUのパフォーマンスを最大15〜30%も低下させる可能性のある固有のオーバーヘッドを生み出します。このパフォーマンスの差は、小規模なタスクでは無視できるかもしれませんが、何百ものGPUで実行される数日間のトレーニングジョブにとっては重大な問題となり、大幅な時間とコストの超過につながります。
パフォーマンスの低下に加え、従来のクラウドサービスの経済モデルは、もう一つの重大な課題を提示します。それはエグレス料金の罠です。AWSは、月間の最初の100GB無料枠を超えたデータ転送(エグレス)に対して、ギガバイトあたり0.09〜0.05ドルを請求し、クラウドからデータを移動させるための帯域幅料金が、しばしばコンピュート自体のコストを超えることがあります。これは、高解像度のビデオ、オーディオ、3Dアセットを扱うメディア企業にとって特に問題となります。Flexentialの「2024年AIインフラ状況レポート」によると、組織の42%がコストとプライバシーの懸念から、AIワークロードをパブリッククラウドから引き揚げています。需要の高いGPUの待ち時間や可用性の問題と組み合わせると、従来のクラウドソリューションの真のコストは、イノベーションに対する重大な障壁となります。
ベアメタルGPU:高性能な代替案
ベアメタルインフラへの移行は、単なるコスト削減のためだけではありません。それは、基盤となるハードウェアの性能ポテンシャルを最大限に引き出すためです。Aethirが提供するような透明な価格モデルにより、組織は従来のソリューションの隠れたコストや複雑さなしに、この優れたパフォーマンスにアクセスできます。GPUへの直接的で妨げのないアクセスを提供することで、ベアメタルソリューションは従来のクラウド環境を悩ませる仮想化のオーバーヘッドを排除します。最近の研究では、最適化された構成を持つGPUアクセラレーションVMはベアメタル性能の95〜100%に達することができると示されていますが、ほとんどの従来のクラウド環境は依然として大幅なパフォーマンス低下に苦しんでいます。この直接的なハードウェアアクセスは、大規模モデルの推論性能における重要な要素であるメモリ帯域幅の最適化にとって極めて重要です。
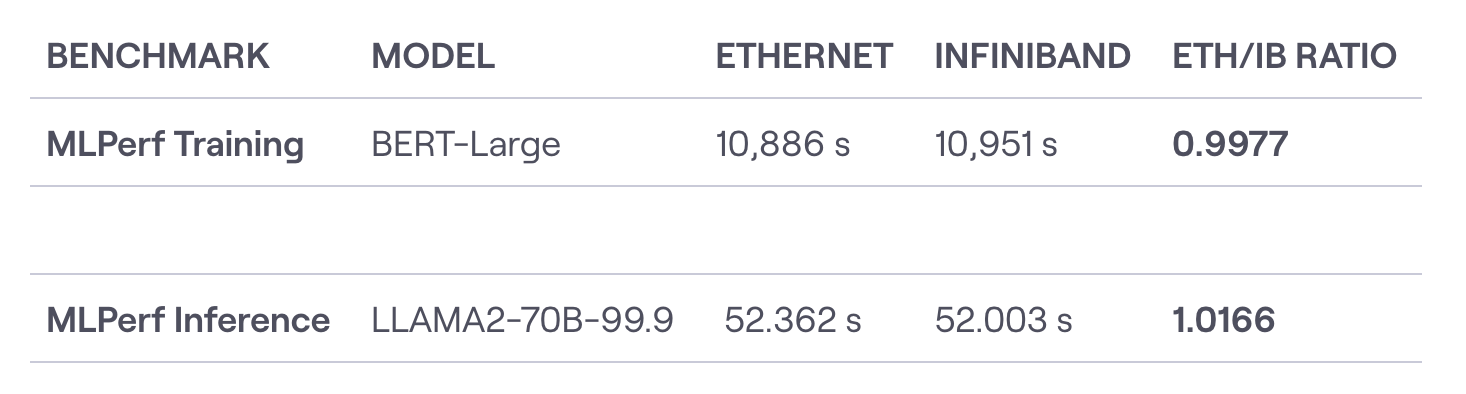
さらに、ベアメタル環境におけるネットワークファブリックは、分散AIワークロードの効率において重要な役割を果たします。InfiniBandのような高性能な相互接続は、標準的なイーサネットに対して大きな利点を提供し、128ノードのGPUクラスターにおいて、InfiniBandは平均1.2マイクロ秒のエンドツーエンド遅延を達成するのに対し、Ultra Ethernetは1.9マイクロ秒です。TensorOperaのFox-1 LLMのケースは、最適化されたインフラを通じて大幅なコスト削減が可能であることを示しており、大幅に削減されたリソース要件で競争力のあるパフォーマンスを達成しています。ハードウェアからネットワークまで、スタック全体を最適化することで、企業は大幅なパフォーマンス向上とコスト削減を実現できます。
IV. ベアメタルインフラで変革されるAIワークロード
ベアメタルインフラの利点は、単一のタイプのAIワークロードに限定されません。それらは生成AIアプリケーションの全スペクトルにわたります。
A. 大規模言語モデル(LLM) LLMにとって、ベアメタルクラスターはトレーニングと推論の両方で大幅な効率向上をもたらします。高性能・低遅延環境で何千ものGPUにスケールする能力は、次世代のマルチモーダルモデルをトレーニングするために不可欠です。
B. 画像およびビデオ生成 メディア生成の領域では、ベアメタルインフラはリアルタイムのレンダリング能力と大規模なバッチ処理を可能にします。ベアメタルソリューションの高帯域幅・低コストのストレージとネットワーキングは、メディアワークフローに関わる膨大なデータセットを管理するために不可欠です。
C. オーディオおよび音楽生成 インタラクティブなオーディオおよび音楽生成アプリケーションの低遅延要件は、ベアメタルインフラに最適です。仮想化のオーバーヘッドを排除することで、開発者はより応答性が高く、魅力的なユーザー体験を創造できます。
D. 3Dコンテンツおよび仮想世界 複雑なシミュレーションや分散レンダリングアーキテクチャにとって、ベアメタルソリューションのGPUダイレクト機能は大きなパフォーマンス上の利点を提供します。これにより、よりリアルで没入感のある3Dコンテンツや仮想世界の創造が可能になります。
V. 構築か、レンタルか:GPUインフラの新たな経済学
AIインフラを構築するかレンタルするかの決定は、あらゆる企業にとって重要です。ベアメタルクラスターの構築には多額の初期投資が必要ですが、革新的な分散型インフラプロバイダーは今や第3の選択肢を提供しています。それは、設備投資や運用の複雑さなしに、エンタープライズグレードのベアメタル性能にアクセスすることです。例えば、単一のH100 GPUの購入には25,000〜40,000ドルかかることがあり、8-GPUクラスターのセットアップには、ネットワーキング、ストレージ、施設コストを考慮する前に、ハードウェアだけで20万ドル以上が必要です。対照的に、Aethirのプラットフォームを通じて同等の容量を1年間レンタルするコストは大幅に低く、メンテナンス、電力、インフラ管理のオーバーヘッドも排除されます。
現代の分散コンピューティングプラットフォームは、エグレス料金や予期せぬ帯域幅料金のない透明な価格設定を提供することで、隠れたコストを排除します。ROI分析では、従来のクラウドプロバイダーと比較して40〜80%のコスト削減が一貫して示されており、ほとんどのワークロードで損益分岐点は通常6〜12ヶ月以内に発生します。
技術的青写真:高性能AIスタックの構築
高性能なベアメタルAIクラスターを構築するには、スタックのすべてのコンポーネントを慎重に検討する必要があります。H100から最新のB200までのGPUの選択は、パフォーマンスとコストに大きく影響します。InfiniBand、RoCE、イーサネット間のネットワークアーキテクチャの決定は、分散ワークロードにとって重要です。VAST、DDN、WekaIOといったプロバイダーのストレージソリューションは、AIワークロードのパフォーマンスを最適化します。クラスターのサイジングは、8-GPUの開発用セットアップから4,096-GPUのスーパークラスターまで様々です。
Aethirのような主要な分散型インフラプロバイダーは、93カ国200以上の拠点にまたがるグローバルネットワーク全体で事前に最適化された構成を提供することで、これらの技術的課題に対処し、組織がインフラ管理の複雑さなしに最適な構成にアクセスできることを保証します。
移行を容易に:エンタープライズAIのための段階的戦略
一般的な移行に関する懸念には、事業継続性、スキル要件、パフォーマンス検証などがあります。成功している組織は、段階的な移行戦略に従います。まず重要度の低いワークロードから始め、パフォーマンスベンチマークを検証し、その後徐々に本番システムを移行します。主な成功要因には、移行中のハイブリッド環境の維持、チームトレーニングへの投資、明確なパフォーマンス指標の確立が含まれます。
ほとんどの組織は、24〜48時間の展開時間と包括的な技術サポートが、従来の予想と比較して移行リスクを大幅に削減することを発見しています。
AIコンピュートの未来:分散化と持続可能性
インフラの状況は、NVIDIAのBlackwell B200やGB200アーキテクチャのような新しいGPU技術が前例のないパフォーマンス向上を約束し、急速に進化しています。分散型インフラのトレンドは、持続可能性への懸念と地理的な分散の必要性によって加速しています。環境への配慮が重要になっており、ベアメタルソリューションは仮想化された代替案と比較して優れたエネルギー効率を提供します。
2025〜2027年の予測には、分散型GPUネットワークの広範な採用、再生可能エネルギー源の統合、そして特定のワークロードタイプに最適化された専門的なAIインフラの出現が含まれます。
高性能な生成AIへのロードマップ
1. 評価フェーズ: 現在のインフラコストを評価し、パフォーマンスのボトルネックを特定し、エグレス料金や隠れた料金を定量化します。ベースラインのパフォーマンス指標を確立するために、既存のワークロードをベンチマークします。
2. パイロットプログラム: 明確なROIを示す、価値の高い、重要度の低いワークロードから始めます。ベアメタルの利点が最も顕著な、高い帯域幅要件を持つアプリケーションや、長時間のトレーニングジョブに焦点を当てます。
3. 主要指標: 総所有コスト(TCO)、パフォーマンスの改善、展開速度、運用効率を追跡します。GPU時間あたりのコスト、トレーニング時間の短縮、インフラの利用率を監視します。
4. パートナーシップアプローチ: 運用の複雑さなしにエンタープライズグレードのインフラを提供するマネージド・ベアメタルサービスを検討し、インフラ管理ではなく、コアのAI開発に集中できるようにします。
ギャップを埋める:Aethirによる生成AIの民主化
優れたパフォーマンス、透明な価格設定、直接的なハードウェアアクセスを備えたベアメタルGPUクラスターは、次のAIイノベーションの波の基盤となりつつあります。Aethirのような分散型プラットフォームは、高性能コンピューティングへのアクセスを民主化し、あらゆる規模の組織が、グローバルネットワークにわたる安全でコスト効率の良いエンタープライズグレードGPUへのアクセスを通じて、AIファースト経済で平等に競争できるようにしています。
競争上の必須事項は明確です。現代の分散型プラットフォームを通じてベアメタルインフラを採用する企業が、「すべてが生成される革命」をリードするでしょう。未来は、ベアメタルGPUクラスターの能力を最大限に活用する人々のものです。そしてAethirは、その未来を誰もが利用できるようにします。
AIインフラを変革する準備はできていますか? 今すぐAethirのエンタープライズチームに連絡して、特定の要件について相談し、ベアメタルGPUクラスターがあなたの生成AIイニシアチブをいかに加速できるかを発見してください。enterprise.aethir.comから始めましょう。




