
Der KI-Boom und das neue Ressourcen-Rennen
Jede Branche versucht, von der KI-Innovation zu profitieren. Von der Beschleunigung der Wirkstoffforschung über die Revolution im Finanzmodellieren bis hin zur nächsten Generation autonomer Systeme – das Rennen zur Integration von Künstlicher Intelligenz hat begonnen. Doch diese Revolution basiert auf einem ganz bestimmten und zunehmend knappen Treibstoff: leistungsstarker GPU-Compute. Dies ist nicht nur eine technische Anforderung; es ist das neue Öl, das den Motor der modernen Innovation antreibt.
Die unstillbare Nachfrage nach Rechenleistung hat einen beispiellosen Engpass geschaffen. Ein aktueller Bericht von McKinsey prognostiziert, dass bis 2030 rund 5,2 Billionen US-Dollar an Investitionen in KI-bezogene Rechenzentren notwendig sein werden, um mit der Nachfrage Schritt zu halten. Traditionelle Hyperscaler haben Schwierigkeiten, diesen Anstieg zu bewältigen, was zu langen Wartelisten für High-End-GPUs, steigenden Kosten und einem Wettbewerbsumfeld führt, in dem der Zugang zu Compute zum entscheidenden Erfolgsfaktor wird.
Quelle: McKinsey
Laut dem Stanford AI Index Report 2025 setzen inzwischen 78 % der Unternehmen KI in mindestens einer Geschäftsfunktion ein – im Vorjahr waren es noch 55 %. Diese explosive Verbreitung hat das geschaffen, was Branchenexperten als „Infrastruktur-Engpass, der KI-Innovation abwürgt“ bezeichnen. Für Unternehmen ist es ein Fehler, Compute lediglich als operative Kostenstelle zu betrachten. In dieser neuen Realität muss es als strategischer Kern-Asset gemanagt werden.
Die Risse in der Cloud: Warum das alte Modell bricht
Das zentralisierte Cloud-Modell, das das letzte Jahrzehnt prägte, zeigt deutliche Schwächen unter dem Druck des KI-Booms. Cloud-Giganten kämpfen weiterhin mit Kapazitätsengpässen, während die KI-Nachfrage steigt – Analysten verzeichnen regelmäßig Enttäuschungen, weil Hyperscaler die Erwartungen nicht erfüllen können. Sich ausschließlich auf einige wenige Hyperscaler für die kritischste Ressource des 21. Jahrhunderts zu verlassen, birgt inakzeptable Risiken.
Die Knappheits-Barriere
Die Marktdynamik der GPU-Knappheit ist dramatisch. Die Tech-Industrie kämpft mit einem massiven Mangel, verursacht durch Produktionsstörungen und einer ungebremsten Zunahme der KI-Nachfrage.
Im ersten Quartal 2025 wies NVIDIA fast 60 % seiner Chipproduktion Unternehmenskunden im KI-Bereich zu – und verringerte so drastisch die Verfügbarkeit für den Rest des Marktes. Hinzu kamen Produktionsstörungen, etwa ein Erdbeben der Stärke 6,4, das mehr als 30.000 High-End-Wafer in TSMC-Fabriken beschädigte.
Die Folge: Der Zugang zu modernster Hardware wie der H100 GPU bedeutet lange Wartezeiten und hohe Aufpreise. High-End-GPUs verkaufen sich inzwischen 30–50 % über Listenpreis, wodurch Projekte verzögert und Innovationen ausgebremst werden. Eine Branchenanalyse fasste es zusammen: „Die KI-Nachfrage überlastet GPUs, Speicher und Netzwerk-ICs“ – und die Knappheit hält trotz gesteigerter Produktion an.
Das Risiko der Zentralisierung
Aus Unternehmenssicht entstehen dadurch zwei wesentliche Risiken:
- Vendor Lock-in: Abhängigkeit von einem oder zwei Hyperscalern verleiht diesen enorme Preismacht und reduziert die strategische Flexibilität. Wird die gesamte KI-Roadmap auf der Infrastruktur eines Anbieters aufgebaut, ist das Unternehmen dessen Preiserhöhungen, Kapazitätsgrenzen und Prioritäten ausgeliefert.
- Innovations-Engpässe: In der schnelllebigen KI-Welt entscheidet Geschwindigkeit über Marktführerschaft. Unternehmen, die ihre KI-Infrastruktur 40 % schneller bereitstellen, erzielen 2,3x mehr Umsatzwachstum und sichern sich 60 % mehr Marktanteil. Wenn der Cloud-Provider die benötigte Kapazität nicht liefern kann, kommt die Produkt-Roadmap zum Stillstand.
Dies hat eine klare Zugangskluft geschaffen: Große Tech-Konzerne können Milliarden investieren, um sich eigene Compute-Lieferketten zu sichern. Start-ups und kleinere Unternehmen – oft die Haupttreiber disruptiver Innovation – kämpfen dagegen um die Ressourcen, die sie benötigen, um zu wachsen.
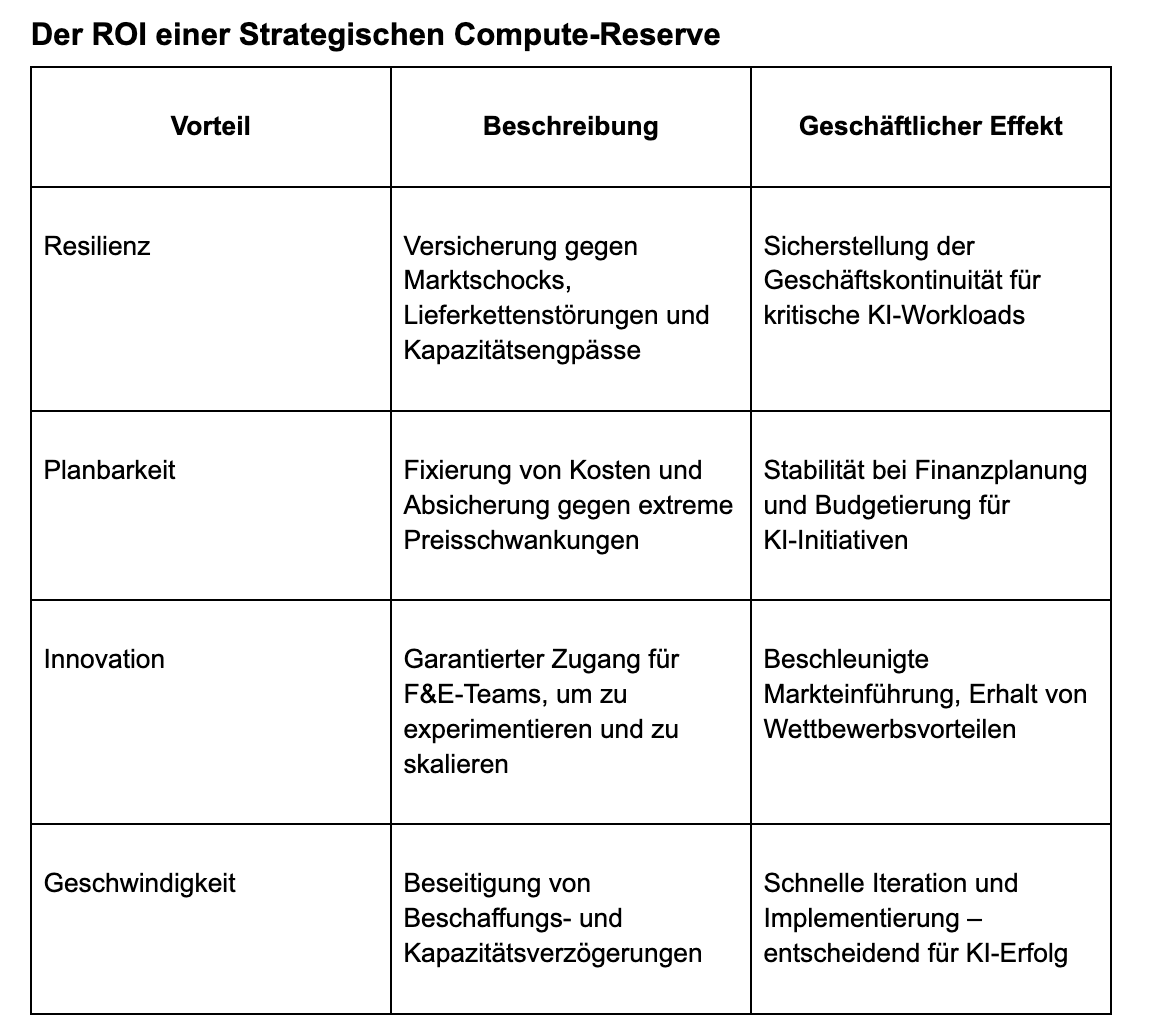
Die Unternehmenslösung: Aufbau einer Strategischen Compute-Reserve
Um in diesem Umfeld erfolgreich zu sein, müssen Unternehmen ihr Vorgehen überdenken. Die Zeit ist reif für das Konzept einer „Compute Treasury“ oder „Strategischen Compute-Reserve“ als Kernfunktion der Unternehmensstrategie und -finanzen.
Dabei geht es nicht darum, physisch Hardware in privaten Rechenzentren zu horten. Sondern um eine clevere Strategie, langfristigen und garantierten Zugang zu Compute-Kapazitäten zu planbaren Kosten zu sichern – vergleichbar mit Fluggesellschaften, die sich gegen Treibstoffpreisschwankungen absichern, oder Herstellern, die sich Rohstofflieferungen langfristig sichern.$
Aethir: Die Infrastruktur für Ihre Compute Treasury
Dieses neue strategische Gebot erfordert eine neue Infrastruktur.
Traditionelle Cloud-Bereitstellungen benötigen 20–32 Wochen – von Beschaffung über Einrichtung bis zum Produktivstart. Wenn die Infrastruktur einsatzbereit ist, sind Marktchancen oft schon vorbei und Wettbewerbsvorteile verloren.
Aethir wurde speziell entwickelt, um diese Probleme zu lösen – durch dezentrale Cloud-Infrastruktur, die Bereitstellungszeiten um 90 % verkürzt.
Vorteile von Aethirs dezentralisiertem Modell:
- Kosteneffizienz: Enterprise-Grade H100 GPUs für 1,25 $ pro Stunde (~900 $ pro Monat bei 24/7 Nutzung) – bis zu 90 % günstiger als traditionelle Anbieter. Inklusive Hochgeschwindigkeits-Speicher und Bandbreite, ohne versteckte Abgaben.
- Globale Verfügbarkeit: Infrastruktur in 94 Ländern mit über 435.000 GPU-Containern. Multi-Region-Deployments mit geringer Latenz, näher bei Nutzern und Datenquellen.
- Schnelle Bereitstellung: Aethirs 2-Wochen-Prozess ersetzt 32 Wochen. Woche 1: Anforderungsanalyse und Infrastruktur-Provisionierung. Woche 2: Modellintegration, Test und Produktionsfreigabe.
- Flexible Architektur: Bare-Metal-Zugang ohne Virtualisierungs-Overhead, InfiniBand und RoCE-Fabrics für High-Throughput, volle Stack-Anpassung.
Fazit: Sichern Sie sich Ihren Treibstoff für die Zukunft
Das Geschäftsargument ist eindeutig: Die KI-Revolution ist eine Compute-Revolution. Das alte Modell, Compute wie ein Versorgungs-Gut einzukaufen, ist nicht mehr tragfähig.
Studien zeigen: Das Vertrauen von Führungskräften in ihre KI-Strategie ist von 53 % auf 71 % gestiegen – getrieben durch 246 Milliarden US-Dollar an Infrastrukturinvestitionen und messbare Geschäftsergebnisse.
Doch Unternehmen ohne formale KI-Strategie erreichen nur 37 % Erfolgsquote bei der Umsetzung – verglichen mit 80 % bei Unternehmen mit klarer Strategie.
Der Aufbau einer Strategischen Compute-Reserve ist nicht mehr optional – sondern eine Grundvoraussetzung für jedes Unternehmen, das im KI-Zeitalter wettbewerbsfähig bleiben will.
Dies erfordert ein Umdenken: Behandeln Sie Compute noch als Kostenposition – oder bereits als den strategischen Kern-Asset, der über die Zukunft Ihres Unternehmens entscheidet?
Die Antwort darauf könnte über Ihre Marktstellung in der KI-Ära bestimmen.
Bereit, Ihre Strategische Compute-Reserve aufzubauen?
Entdecken Sie, wie Aethirs Infrastruktur der Enterprise-Klasse Ihre KI-Strategie transformieren kann. Besuchen Sie Enterprise AI, um mehr über unsere verteilte GPU-Cloud zu erfahren, oder kontaktieren Sie unser Team direkt, um Ihre spezifischen Compute-Anforderungen zu besprechen.
In der nächsten Ausgabe unserer Serie beleuchten wir, wie Aethirs Tokenomics und das ATH-Ökosystem den perfekten Mechanismus zum Aufbau und Management Ihrer Strategischen Compute-Reserve liefern.




