
在华盛顿特区举办的NVIDIA GTC大会上,一台配备10万块Blackwell GPU的超级计算机以及“千亿级AI工厂”(gigascale AI factories)的愿景正式公布,这一宣言明确传递出一个信号:巨规模AI基础设施时代已经到来。
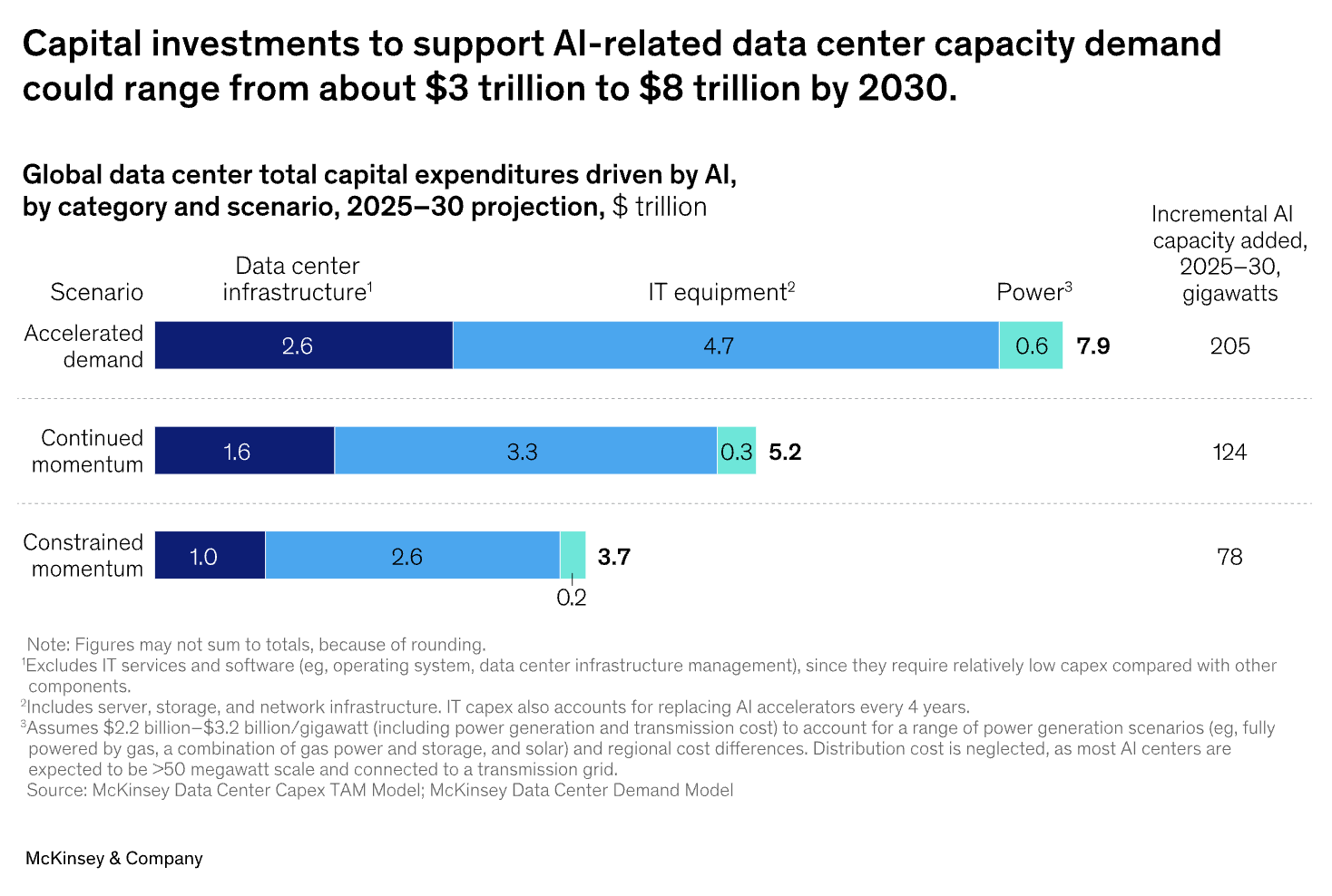
然而,这种扩展伴随着令人震惊的价格标签。根据麦肯锡的数据,到2030年,全球数据中心容量需求预计将需要近 7万亿美元 的资本支出(CapEx),其中绝大部分将用于AI工作负载。这对全球企业提出了一个核心问题:如何在不背负沉重资本支出负担的前提下,利用AI的变革力量?
答案在于一场根本性的金融转变——从“拥有基础设施”转向“访问基础设施”,即按需消费的GPU即服务(GPUaaS)模型。
Aethir的去中心化GPU云采用全球分布式GPU即服务模式,利用435,000+高端GPU容器支持企业级AI与游戏算力任务。通过分布于93个国家、200多个地区的独立云主机,Aethir的DePIN架构提供了无与伦比的去中心化GPU云服务,在可扩展性与成本效率方面远超昂贵的中心化云。目前已有150多个客户与合作伙伴使用Aethir的分布式GPU即服务模式,充分展示了AI创新如何在去中心化基础设施上蓬勃发展。
Source: McKinsey
AI基础设施的资本支出困境
传统的AI扩展模式是一场以资本支出(CapEx)为核心的竞赛:谁能最快购买并部署更多硬件。然而,这种模式问题重重。麦肯锡预测的数万亿美元投资凸显了巨大的入场门槛,并形成他们所谓的“投资困境”:过度投资会导致昂贵资产闲置,而投资不足则意味着在竞争中被甩在后面。
2024年10月,OpenAI与微软的高层公开承认,他们的AI算力需求已远超现有容量。而这一问题还被隐藏成本进一步放大——这些成本远超GPU本身的购置价格。高速网络、先进散热系统、庞大的供电设施以及持续的维护费用,共同构成了一个总拥有成本(TCO),其规模常常远超初始硬件投资。
此外,研究显示,全球超过一半的GPU容量在任何时刻都是闲置的,这意味着巨大的资本浪费与资源低效。
运营支出的优势:GPU即服务如何重塑AI经济
GPU即服务(GPUaaS)彻底颠覆了传统模式,将硬件采购的高额资本支出(CapEx)转化为灵活、可预测的运营支出(OpEx)。
组织不再需要“拥有”,而是“按需使用”。这种模式带来了一系列战略优势,正在重新定义AI的经济逻辑。
市场已经明确验证了这一趋势。GPU即服务行业在2023年的市场规模为 32.3亿美元,预计到2032年将增长至近 500亿美元,标志着行业正全面转向按需消费模式。
NVIDIA GTC 2025:基础设施转折点的信号
NVIDIA GTC大会上的公告是行业拐点的有力信号。
CEO黄仁勋提出的“千亿级AI工厂”愿景,以及他所言“AI基础设施是一个需要数百家公司协同的生态级挑战”,强调了现代AI部署的巨大复杂性。部署超过10万块GPU的系统规模,使得传统的“自有基础设施模式”变得对除少数全球巨头外的公司而言不再现实。
同时,政府、企业与云服务商(如美国能源部DOE、Oracle、Uber)之间的合作,更突显了行业从单一、封闭数据中心向分布式、互联、灵活生态系统的转型。
未来的AI基础设施将属于按需消费模式的生态,在这种协同环境中提供敏捷性与参与门槛的降低。
战略转变:为什么运营支出模式正在胜出
转向运营支出(OpEx)不仅仅是财务操作,更是一种战略必然。
行业领导者强调,通过“制冷即服务”(Cooling-as-a-Service)和“能源即服务”(Energy-as-a-Service)等新型灵活金融模式,将CapEx转移至OpEx预算,以满足关键业务指标。这种方式让企业专注于自身核心竞争力——开发创新的AI应用,而非充当数据中心运营商。
这一战略转型同样由效率与可持续性驱动。
通过利用全球现有但闲置的GPU资源池,像Aethir这样的分布式GPU即服务平台减少了新建高能耗数据中心的需求。这不仅降低了AI开发的碳足迹,也减少了技术快速迭代带来的过时风险。
最终,OpEx模式让企业级AI基础设施的使用权民主化,使初创公司与研究者也能平等获得高性能计算资源。
未来属于灵活性
在现代AI扩展中,真正的挑战本质上是金融架构问题。
过去依赖重资产投入(CapEx)的模式,已不适用于当下快速创新、需求不确定、规模空前的时代。未来属于那些保持敏捷的组织,而财务灵活性正是关键。
通过GPU即服务平台(如Aethir的分布式云基础设施)交付的运营支出模型,为企业提供了解决方案:在无需巨额前期投资的情况下,获取强大的计算力。
随着AI竞赛加剧,高效、智能的可扩展能力将成为决定性差异化因素。
在这一新范式中,财务敏捷性不仅是一种优势,更是与算力本身同等重要的核心竞争力。
准备好为你的AI扩展获得财务灵活性了吗?
立即联系 Aethir,探索我们的去中心化GPU云如何通过灵活、基于OpEx的基础设施,提供企业级算力支持。




