
Key Takeaways
- Aethir is uniquely positioned to play a key role in the global AI inference economy.
- Distributed AI inference infrastructure enables Aethir to service clients cost-efficiently regardless of location.
- Aethir cuts AI inference costs while providing reliable, flexible, and efficient compute services to all types of AI enterprises, at scale.
From Model Training to the Inference Gold Rush
The AI industry has become one of the main drivers of high-performance compute consumption. Various AI integrations and workloads, such as AI model training, agent training, generative AI, robotics management, and other innovative features, are extremely compute-intensive. The AI sector’s rapid expansion requires massive compute for inference, which centralized clouds can’t provide cost-effectively. Modern AI integrations need versatile, readily available, and efficient cloud computing support, which is precisely what Aethir’s decentralized GPU cloud offers to enterprise customers worldwide.
AI’s value is no longer created primarily at training time, but during continuous inference, which requires constant access to premium GPU cloud computing services. Every query, prompt, prediction, and real-time decision runs complex computations in the background on high-end GPUs such as NVIDIA H200s.
Furthermore, the rise of production AI, such as LLMs, agents, copilots, recommendation systems, and vision models, along with their integration into daily business processes, incurs additional GPU computing expenses for companies.
Available data shows that the global AI inference economy is projected to exceed $250B by 2030, growing at 19.2% CAGR. However, to provide the inferences needed by AI trailblazers, companies need to run AI profitably at scale. This is where Aethir’s decentralized GPU cloud is perfectly positioned as a critical support pillar for large-scale AI inference workloads.
Why Inference Costs Are Becoming the Dominant AI Bottleneck
Inference costs can make or break a company’s AI business venture because of the high market costs of traditional, centralized cloud providers. This is creating a massive AI bottleneck because constant access to reliable high-performance cloud computing can be quite expensive for clients. Luckily, Aethir’s decentralized GPU cloud model offers an alternative, much more affordable solution.
Inference workloads are typically:
- Always-on
- Latency-sensitive
- Volume-driven (millions/billions of calls)
- Unlike training, inference costs never stop once an application is live.
Traditional cloud providers have a hard time keeping up with the rising demand for inference because their robust, static infrastructure can’t dynamically allocate resources in real time.
Traditional cloud constraints include:
- Premium pricing for on-demand GPUs
- Poor cost efficiency for steady-state inference
- Overprovisioning and idle capacity are included in pricing, leading to high service costs.
All of these factors lead to unsustainable AI inference costs for clients. Ultimately, this can result in AI products failing not because demand is low, but because inference economics don’t scale. Enterprises must optimize their inference infrastructure to outperform competitors.
Aethir’s decentralized GPU cloud offers clients an innovative AI inference pricing strategy that only charges for the compute clients actually use. There are no vendor lock-in risks, added costs, or long GPU provisioning queues.
The Infrastructure Shift: From Centralized Clouds to Decentralized GPU Networks
Centralized clouds require significant upfront CapEx and heavily depend on lengthy GPU procurement cycles, which are prone to delays due to geopolitical circumstances and supply chain bottlenecks. The decentralized GPU cloud model, pioneered by Aethir’s AI inference infrastructure, flips the script by circumventing centralized cloud services, focusing on flexible OpEx.
Aethir’s GPU inference cloud aggregates underutilized and distributed GPU capacity into a unified inference layer, cutting AI deployment costs through cost-optimized inference infrastructure. Companies don’t need to pay hyperscaler premiums. Instead, they can leverage Aethir’s massive, decentralized global network of nearly 440,000 high-performance GPU Containers across 94 countries and 200+ locations. Aethir offers a cost-effective GPU cloud for AI inference scaling.
Why AI inference workloads work great with Aethir’s decentralized GPU cloud model?
Inference workloads are:
- Highly parallelizable
- Predictable demand patterns
- Less training-specific customization required
These characteristics make AI inference an excellent match for Aethir’s decentralized GPU cloud infrastructure, which is purpose-built to reduce AI inference costs.
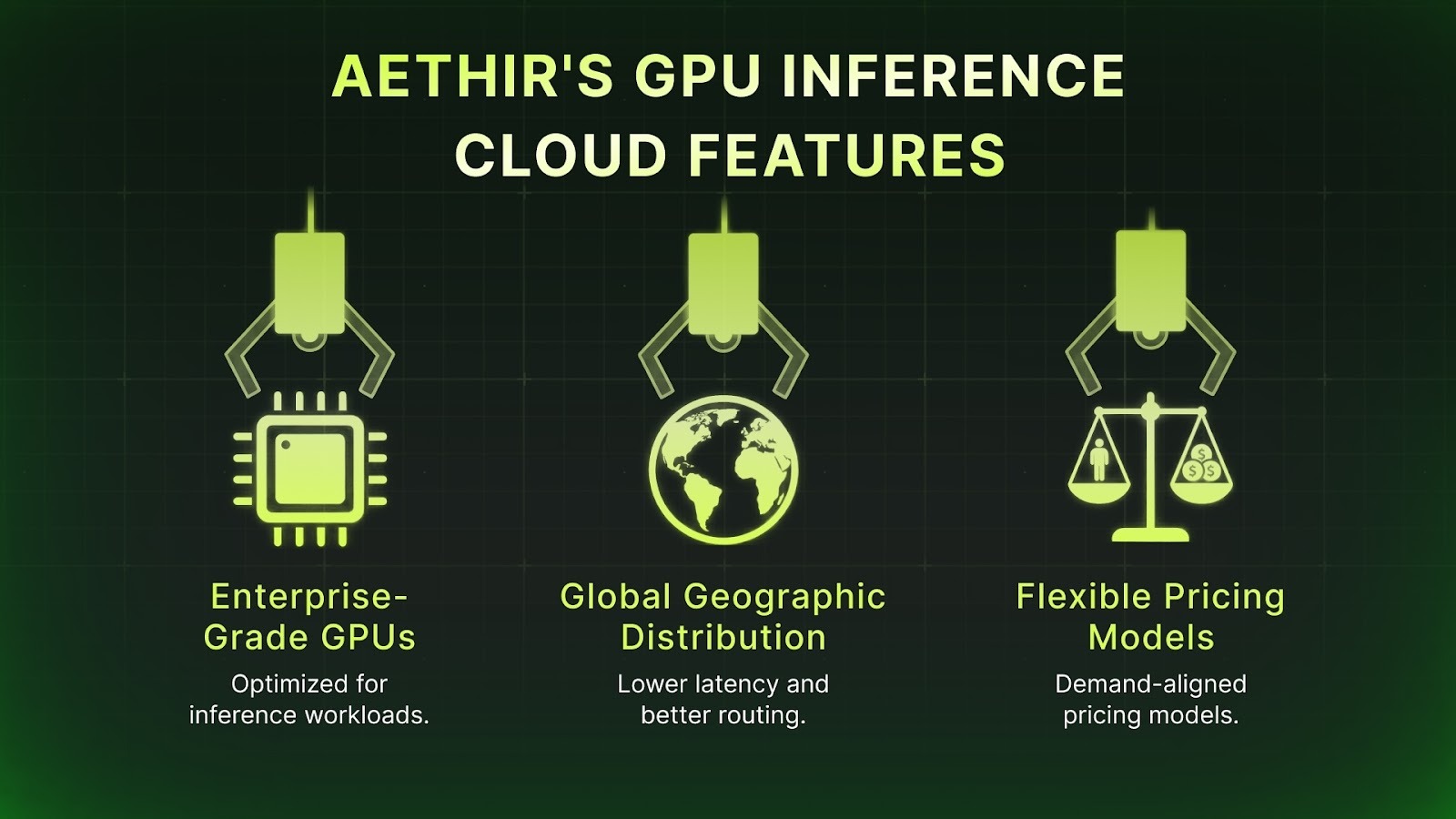
Our GPU inference cloud offers companies in need of AI infrastructure:
- Enterprise-grade GPUs optimized for inference workloads
- Global geographic distribution: lower latency, better routing.
- Flexible, demand-aligned pricing models
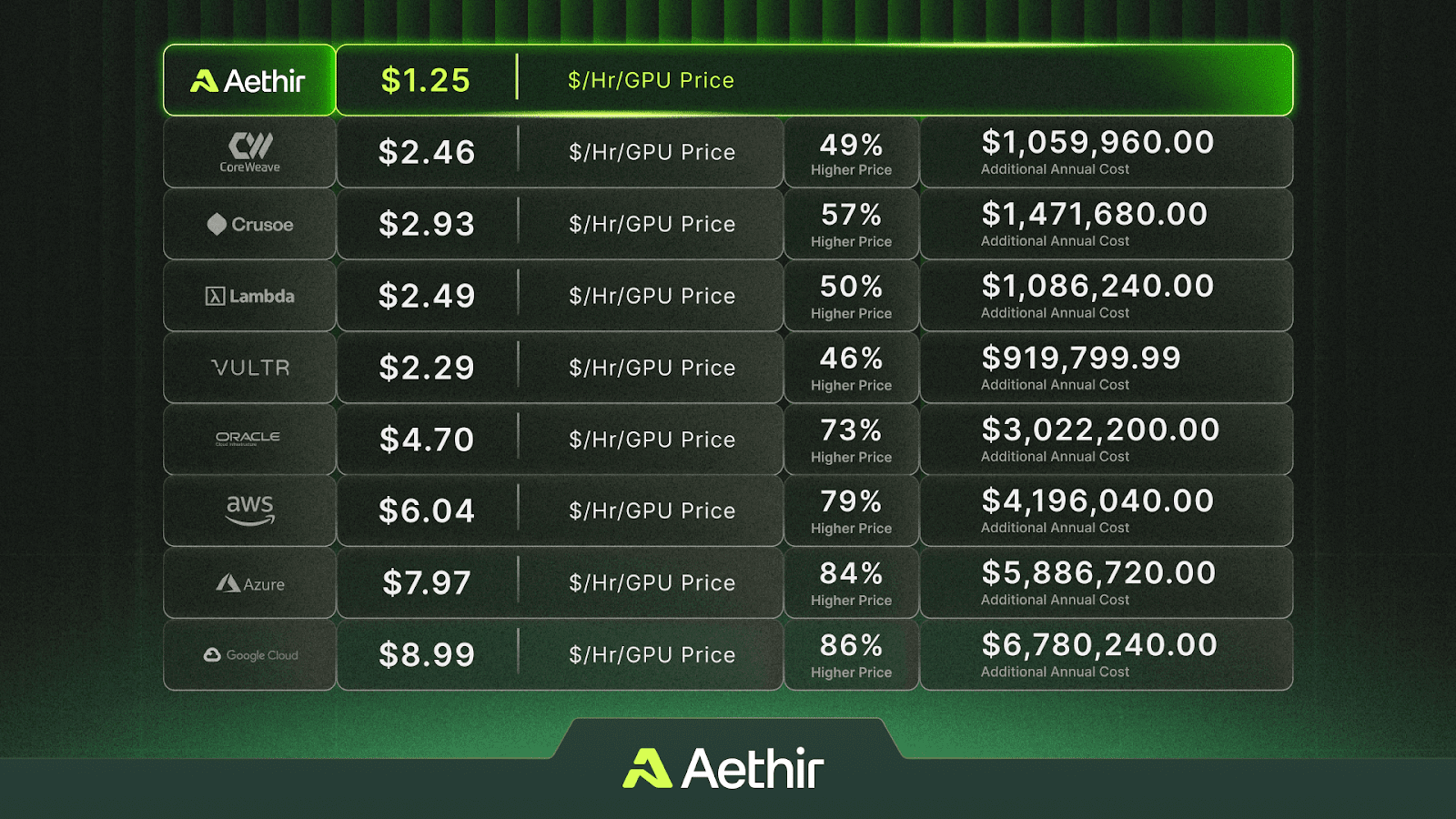
Unlike centralized hyperscalers, Aethir’s decentralized GPU cloud offers a flexible, cost-effective AI inference infrastructure that delivers up to 86% lower inference costs than traditional clouds.
How Aethir Enables Cost-Optimized, Scalable AI Inference
Aethir’s decentralized GPU cloud provides enterprise-grade AI inference services to 150+ clients and partners across the AI, Web3, and gaming sectors worldwide. We leverage a distributed network of independent Cloud Hosts, inference infrastructure providers who earn ATH tokens for providing GPU compute to our global pool of clients.
Cost efficiency is one of Aethir’s key selling points compared to centralized hyperscalers. By distributing infrastructure across 200+ regions, we enable companies to reduce AI inference costs with decentralized GPUs. Furthermore, Aethir offers elastic scalability, allowing clients to dynamically scale their AI inference consumption as needed to support product development pipelines.
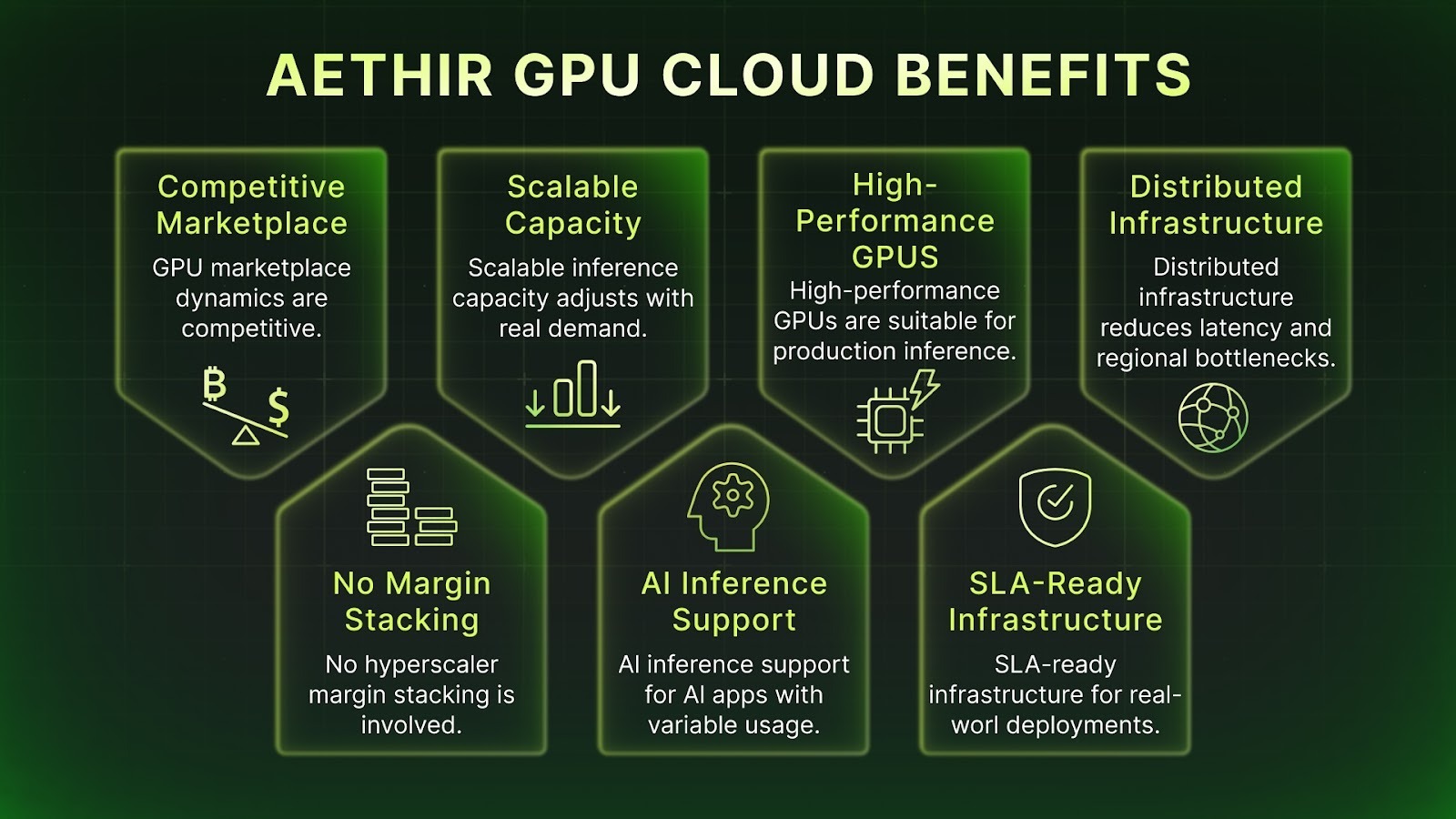
Aethir’s GPU inference cloud offers:
- Competitive GPU marketplace dynamics
- No hyperscaler margin stacking
- Scalable inference capacity up/down with real demand
- AI inference support for AI apps with variable usage
- High-performance GPUs suitable for production inference
- SLA-ready infrastructure for real-world deployments
- Distributed infrastructure that reduces latency and regional bottlenecks
Centralized hyperscalers can only provide AI inference infrastructure at inflated prices, allowing big tech companies to monopolize it by paying the high costs of centralized cloud services. Aethir offers an accessible GPU inference cloud that enables developers to design AI products around sustainable inference costs, not inflated cloud pricing.
In the Inference Economy, Infrastructure Is the Moat
Numerous global industries are heavily incorporating AI capabilities into their product pipelines and daily operations, but to win against competitors, companies must run AI inference more cheaply, faster, and longer. In a world where everyone is integrating AI into their businesses, AI deployment costs will be a decisive factor in achieving a competitive advantage.
Infrastructure is the moat of the inference economy. With Aethir’s decentralized GPU cloud, companies have trustworthy, cost-optimized inference infrastructure at their disposal for innovative AI inference tasks that make a difference in today’s AI-powered economy.
Innovative AI inference use cases powered by Aethir:
- LLM-powered SaaS platforms
- AI agents and copilots
- Real-time inference for gaming, vision, and recommendation systems
- Web3 and AI-native applications with global user bases
As the inference economy accelerates toward $250B+, decentralized GPU infrastructure becomes a foundational layer for enabling global AI innovation across various industries.
Aethir’s decentralized GPU cloud is the global leader in shifting AI inference from centralized hyperscaler cloud models to a versatile, market-driven, cost-effective infrastructure.
Discover Aethir’s enterprise-grade AI inference infrastructure and learn more about our GPU cloud compute offering here.
Apply to become an Aethir Cloud Host and start monetizing your idle GPUs by filling out this form.
FAQs
What is the AI inference economy?
The AI inference economy refers to the market for running trained AI models in production, where value is created through continuous, high-volume inference.
Why are AI inference costs becoming a major bottleneck?
Inference workloads are always-on, latency-sensitive, and scale with usage, making centralized cloud pricing unsustainable as AI applications grow. Aethir offers a cost-efficient alternative for AI inference infrastructure.
Why is decentralized GPU infrastructure ideal for inference workloads?
Inference is highly parallelizable and predictable, making it well-suited for distributed GPU networks that deliver lower costs, better utilization, and global low-latency access.
How does Aethir reduce AI inference costs?
Aethir aggregates underutilized GPUs into a global decentralized cloud, offering transparent pricing, elastic scaling, and up to 86% lower inference costs than traditional hyperscalers like Google Cloud.




